
GPT-4:GPT的一小步,多模态AI的一大步 原创
在ChatGPT风靡全球数月后,OpenAI终于发布了它的大型多模态模型(large multimodal model)GPT-4,它不仅能与用户一起生成、编辑,完成创意的迭代和技术写作任务,更重要的是,它还能读懂图片。

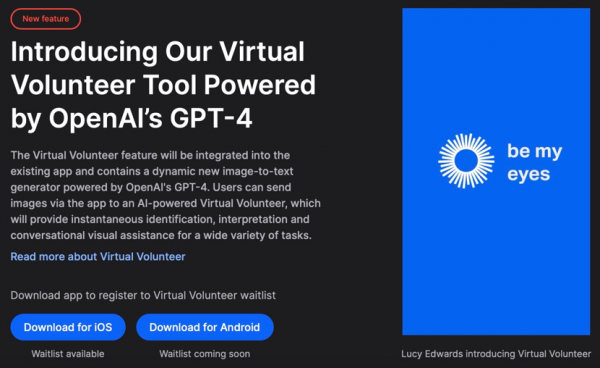
OpenAI称,GPT-4“比以往任何时候都更有创造性”,可以“更准确地解决问题”。官方在这次的发布过程中也提到一些合作方,包括Duolingo、Stripe、Khan Academy等。其中,引入GPT-4之后,改变最为明显的就是一款叫“Be My Eyes”的应用。
Be My Eyes在全世界拥有600多万名志愿者和视障与盲人用户,志愿者可以帮助用户介绍摄像头拍摄的画面。GPT-4成为这个平台上的第一个虚拟志愿者,用户可以向这个虚拟志愿者传送图像,提供即时识别、解释,并且以对话的形式提供协助。
以往的GPT-3.5无法将上述操作变成现实,因为它不具备识别图片的能力。这也是GPT-4作为一个大型多模态模型,与ChatGPT的GPT-3.5最大的不同之处。
简单来说,GPT-3.5能够在一定程度上理解并使用人类的语言,而GPT-4则是具备以人类的视角理解图像的能力。
官方给出的一些案例也令人惊艳,它可以帮你解释一些迷因梗图,或指出图片中不自然的地方,或是根据简单的几幅图片给出说明,甚至可以看图总结论文、回答试卷中的问题。
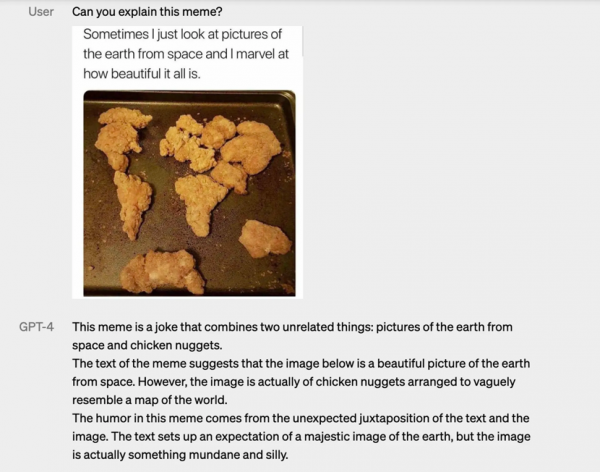
GPT-4清楚解释了上面这幅梗图的含义

GPT-4指出了图中不自然的地方

GPT-4分别解释了图中每一格的画面内容

GPT-4分别回答了图片中的问题
多模态对GPT-4这样的生成式AI来说意义重大,除了Be My Eyes的例子,未来还可望应用到一些设计工具和图像处理产品上,连OCR(光学字符识别)技术也要甘拜下风了。
视频翻译产品Targum Video的创办人Altryne也表示,GPT-4的图像理解能力已经甩开现有模型数里地。
不过遗憾的是,OpenAI还没有把图像输入能力开放给公众体验,目前我们可以通过付费订阅ChatGPT Plus或Quora Poe来尝鲜。那么不会“看图说话”的GPT-4比GPT-3.5强在哪里呢?我们也通过Quora的Poe询问了一下GPT-4“本人”:
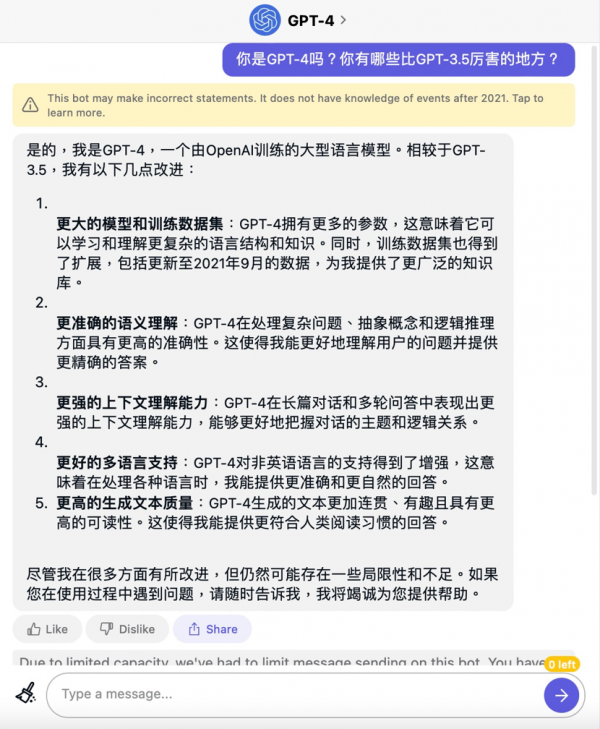
总的来说,相比GPT-3.5,GPT-4拥有更丰富的知识,对人类语言的理解能力也更准确,可以更好的理解整体对话的主题,不像以前那样一不小心就“歪楼”,非英语的语言理解能力也有所增强,生成的文本也会更连贯,可读性更高。
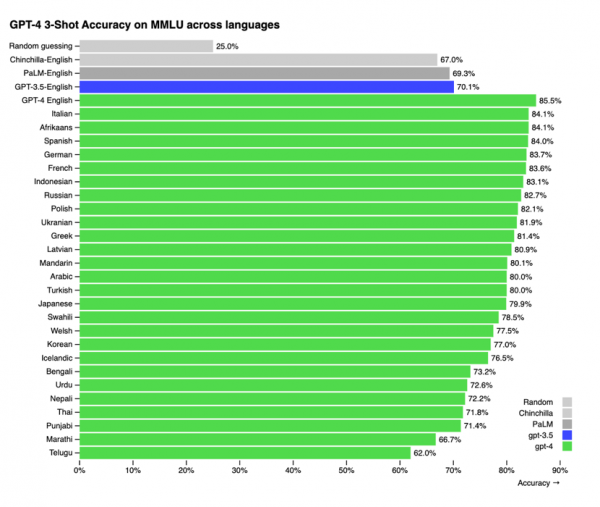
根据官方公布的数据,GPT-4不仅具备理解图片的能力,语言处理能力也有很大进步,GPT-4的中文能力已经超越GPT-3.5的英文能力了。
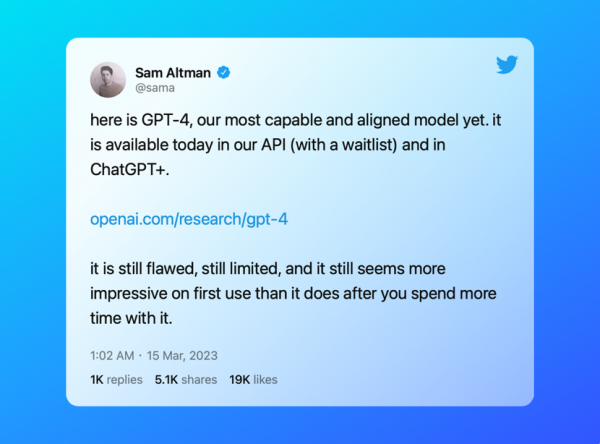
不过OpenAI CEO Sam Altman在Twitter上表示,GPT-4“仍然有局限性”,而且“第一次使用时似乎比你花更多时间使用它时更令人印象深刻”。
也就是说,仅从使用体验出发,GPT-4在语言能力上的改变更多体现在一些细微之处,不会像ChatGPT刚出现时那样惊为天人,不过对于多模态AI的实现来说,GPT-4的出现确也让人类再次迈出具有历史意义的一大步。
好文章,需要你的鼓励


AI推动KubeCon NA 2025平台工程复兴浪潮
在2025年KubeCon/CloudNativeCon北美大会上,云原生开发社区正努力超越AI炒作,理性应对人工智能带来的风险与机遇。随着开发者和运营人员广泛使用AI工具构建AI驱动的应用功能,平台工程迎来复兴。CNCF推出Kubernetes AI认证合规程序,为AI工作负载在Kubernetes上的部署设定开放标准。会议展示了网络基础设施层优化、AI辅助开发安全性提升以及AI SRE改善可观测性工作流等创新成果。

维吉尼亚理工学院破解单细胞生物学新密码:当大语言模型遇见细胞世界的奇妙变革
维吉尼亚理工学院研究团队对58个大语言模型在单细胞生物学领域的应用进行了全面调查,将模型分为基础、文本桥接、空间多模态、表观遗传和智能代理五大类,涵盖细胞注释、轨迹预测、药物反应等八项核心任务。研究基于40多个公开数据集,建立了包含生物学理解、可解释性等十个维度的评估体系,为这个快速发展的交叉领域提供了首个系统性分析框架。

DeepL CEO:专业翻译服务如何在ChatGPT时代保持竞争优势
DeepL作为欧洲AI领域的代表企业,正将业务拓展至翻译之外,推出面向企业的AI代理DeepL Agent。CEO库蒂洛夫斯基认为,虽然在日常翻译场景面临更多竞争,但在关键业务级别的企业翻译需求中,DeepL凭借高精度、质量控制和合规性仍具优势。他对欧盟AI法案表示担忧,认为过度监管可能阻碍创新,使欧洲在全球AI竞争中落后。

西湖大学团队突破:AI推理模型内存消耗降低50%的秘密武器
西湖大学王欢教授团队联合国际研究机构,针对AI推理模型内存消耗过大的问题,开发了RLKV技术框架。该技术通过强化学习识别推理模型中的关键"推理头",实现20-50%的内存缩减同时保持推理性能。研究发现推理头与检索头功能不同,前者负责维持逻辑连贯性。实验验证了技术在多个数学推理和编程任务中的有效性,为推理模型的大规模应用提供了现实可行的解决方案。
2023
03/15
16:10
分享
点赞

全球数据中心电力需求暴涨,超越电网建设速度
FMC获得FERAM资金以终结Optane的阴霾
AI驱动垂直市场的商业变革与未来机遇
谷歌计划在德州投资400亿美元建设数据中心
AI推动KubeCon NA 2025平台工程复兴浪潮
DeepL CEO:专业翻译服务如何在ChatGPT时代保持竞争优势
提示工程迎来协作提示新技术,让AI成为你的合作伙伴
益博睿的悄然转型:从信用评级到云端AI
特斯拉首次发布更诚实的FSD碰撞数据
GPU巨头正在吞噬超级计算领域,传统存储难以满足需求
MinIO推出EB级ExaPOD存储方案保持AI GPU高效运行
Quantum推出ActiveScale部分对象恢复功能显著提升磁带检索速度
当超1/4美国高中生用ChatGPT学习:一场静默的教育革命正在发生
Sam Altman最新博文《反思》:有信心构建AGI,2025年首批AI智能体将“加入劳动力大军”
惊喜!Sam Altman确定OpenAI新产品,AGI、Agents、成人模式
2024,AI这一年
ChatGPT可视频通话,距离“Her”越来越近 (Day 6/12)
突破性功能!OpenAI发布ChatGPT Projects,万能工具箱上线!
谷歌发布双思维AI Agent:像人类一样思考,重大技术突破!
OpenAI精心打造的Sora视频生成工具疑遭泄露
王者归来!Greg重返OpenAI,主抓重大技术创新
突发!OpenAI正式发布ChatGPT网络搜索,彻底颠覆谷歌!
