
手机大模型的又一股势力?Hugging Face公布SmolLM模型
Hugging Face最近公布了一套新的紧凑型语言模型——SmolLM,这套模型在性能上超越了微软、Meta以及阿里巴巴千问系列的同类产品。这些新模型能够为个人设备提供先进的AI功能,且不会影响到设备端性能与用户隐私。
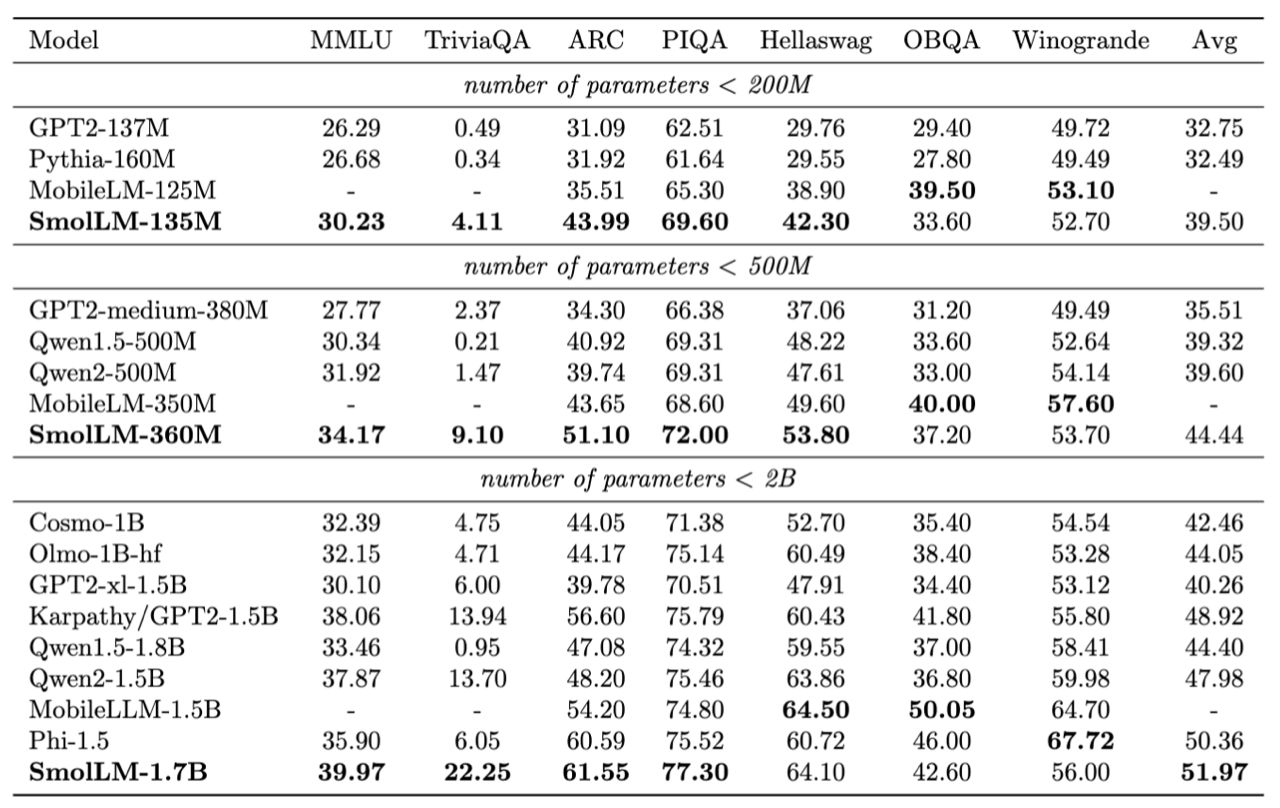
SmolLM家族拥有三位成员,参数规模分别为1.35亿、3.6亿及17亿,旨在适配不同水平的计算资源。尽管占用空间不大,但这些模型在常识推理与世界知识基准测试当中均拥有出色表现。
身小力不亏:SmolLM如何挑战AI行业巨头
Hugging Face公司SmolLM项目首席机器学习工程师Loubna Ben Allal强调,这些紧凑模型在针对特定场景时拥有相当出色的实践效果。她解释称:“我们不需要为每项任务分别建立大规模基础模型,正如我们没必要用拆除锤在墙上打眼儿。专为特定任务设计的小模型也能做好很多工作。”
其中体量最小的SmolLM-135M模型尽管在训练阶段使用的token更少,但表现仍然优于Meta的MobileLM-125M。SmolLM-360M号称在性能上超越了所有参数低于5亿的模型,包括Meta及阿里千问系列产品。旗舰级模型SmolLM-1.7B则在多项基准测试中击败了微软的Phi-1.5、Meta的MobileLM-1.5B以及千问Qwen2-1.5B。
Hugging Face还将包括数据管理到各训练步骤在内整个开发过程进行了开源,迅速获得业界关注。这种透明度也符合该公司对于开源价值主张以及支持可重复研究的承诺。
秘诀:高质量数据管理推动SmolLM获得成功
这些模型的出色表现,离不开精心策划的训练数据。SmolLM以Cosmo-Corpus为基础,其中包括Cosmopedia v2(合成教书与故事内容)、Python-Edu(教育性Python示例)以及FineWeb-Edu(精选的教育性网络内容)。
Ben Allal在采访时解释道:“通过SmolLM的现实性能,我们证明数据质量是决定模型水平的关键因素。我们开发出的创新方法能够精心策划高质量数据,将网络来源与合成数据相结合,从而建立起性能最佳小模型。”
SmolLM的发布也有望对AI的可及性及用户隐私产生重大影响。这些模型完全可以在手机及笔记本电脑等个人设备上运行,因此消除了云计算需求,同时缓解了成本与隐私问题。
推动AI大众化:SmolLM对可及性与隐私的影响
Ben Allal还专门强调了SmolLM家族的可及性优势:“这些能够在手机和个人电脑上运行、且性能出色的小模型,意味着每个人都可以使用AI技术。这些模型能够免费解锁新的可能性,具备完全隐私保障和更低的环境足迹。”
Hugging Face研究团队负责人Leandro von Werra在采访时还特别强调了SmolLM的实际意义。“这些紧凑型模型为开发人员和最终用户打开了一个充满可能性的世界。从个性化自动补全功能到解析复杂的用户请求,SmolLM无需昂贵的GPU或者云基础设施即可支撑起自定义AI应用程序。无论是降低AI的访问门槛、还是为每个人提供隐私保护,SmolLM的出现都代表着迈向未来的重要一步。”
像SmolLM这样强大、高效的小模型,也代表着AI技术迎来了重大转变。通过令高级AI功能更易于访问且符合隐私保护需求,Hugging Face解决了人们对于AI环境影响以及数据隐私等潜在威胁的日益增长的担忧。
随着SmolLM模型家族、数据集以及训练代码的正式亮相,全球AI社区及开发人员现在已经可以探索、改进并构建这种创新的语言模型方法。正如Ben Allal在采访中做出的总结:“希望更多人参与进来,帮助SmolLM更上一层楼!”
来源:VentureBeat
好文章,需要你的鼓励


仿人机器人视觉与运动技术的精细调校
仿人机器人与自动驾驶汽车在区域架构、功能安全及雷达传感方面高度相似。多分辨率摄像头组合可更好地模拟人类视野,兼顾广角低保真与局部高精度需求。自然运动需实时计算正逆运动学、距离与深度,同时须兼顾功耗效率。当前视觉与基础操控技术最为成熟,而触觉、全身协调及非结构化环境中的移动能力仍是主要挑战。业界正借鉴自动驾驶经验,加速推进仿人机器人的规模化落地。

当AI做“陪练老师“:弗吉尼亚理工大学等机构用大模型的“解题日记“预测考题难度
这项研究提出Epi2Diff方法,通过将大型推理模型的解题思考过程拆解为认知片段序列,提取过程特征预测考题对人类的难度,在四个真实考试数据集上超越了所有对比基线。

抵御AI驱动的数据融合攻击:芯片安全防护的关键挑战
随着AI技术发展,攻击者可融合白市、灰市及黑市数据,构建个人及其环境的数字孪生体,使定向攻击更为便捷。专家指出,AI与网络安全的核心交汇点是数据本身。防御AI数据融合攻击需依赖硬件信任根、强加密、安全密钥存储及严格的数据匿名化措施。芯片架构师需将安全设计嵌入硬件层,确保数据完整性验证、隔离执行及认证数据流,以应对日益复杂的运行时攻击面。

南京大学联手阿里巴巴:让AI图像生成变得更“聪明“,一个让图像生成模型真正理解画面的新框架
南京大学与阿里巴巴提出MIMFlow,将掩码图像建模与标准化流端到端融合,让生成模型专注语义建模,以更少参数和更少令牌在ImageNet上取得FID 2.50的优异表现。
2024
07/19
10:52
分享
点赞

仿人机器人视觉与运动技术的精细调校
抵御AI驱动的数据融合攻击:芯片安全防护的关键挑战
AI数据中心与汽车行业在能源管理领域的技术融合
GLM-5.2海外爆火,我们翻了1500条评论,看看用户在讨论什么
电动自行车的功过之辩:被忽视的那一面
Neo:印度科技大亨自掏3000万美元,打造微软Office的AI替代品
AI数据中心如何获得电网接入资格?公用事业公司的规划逻辑解析
Brookfield与Bloom能源将融资规模扩至250亿美元,押注AI数据中心独立供电
当CIO的技术提案遭到否决,该如何应对?
这款谷歌实验室 AI 应用如何成为我每日必用的工具
起亚EV5推出Storm特别版并新增全轮驱动选项
Meta效仿SpaceX,将过剩AI算力变现
