
好莱坞告急!OpenAI发布Sora模型,瞬间生成高清大片 原创
OpenAI这两天发布一款名为“Sora”的视频生成AI,和许多视频生成工具一样,用户只要给出文字叙述或静态图片,Sora 就能自动生成 1080p 的动画,可以支持各种不同的角色、动作类型和背景画面。
“Sora”的名称源自日语的“天空”(そら),能够生成长达1分钟的视频,光是这一点就已经超越当前许多同类产品。OpenAI 已经向一些研究人员和创作者开放 Sora 的访问权限,OpenAI 在社交平台 X 发布的范例视频中,可以看到细腻的场景、复杂的运镜和情绪饱满的角色。

Sora 使用约10000 小时的”高品质“视频训练,OpenAI 表示,Sora 基于DALL·E、GPT 模型的研究成果,一方面使用DALL·E 3 的重述技术,能为视觉数据生成高度描述性的标题,所以Sora 可以更好地遵循用户的指令,生成情感丰富、引人入胜的角色,甚至还能深入理解指令提到的人、事、物在现实世界中的样子。
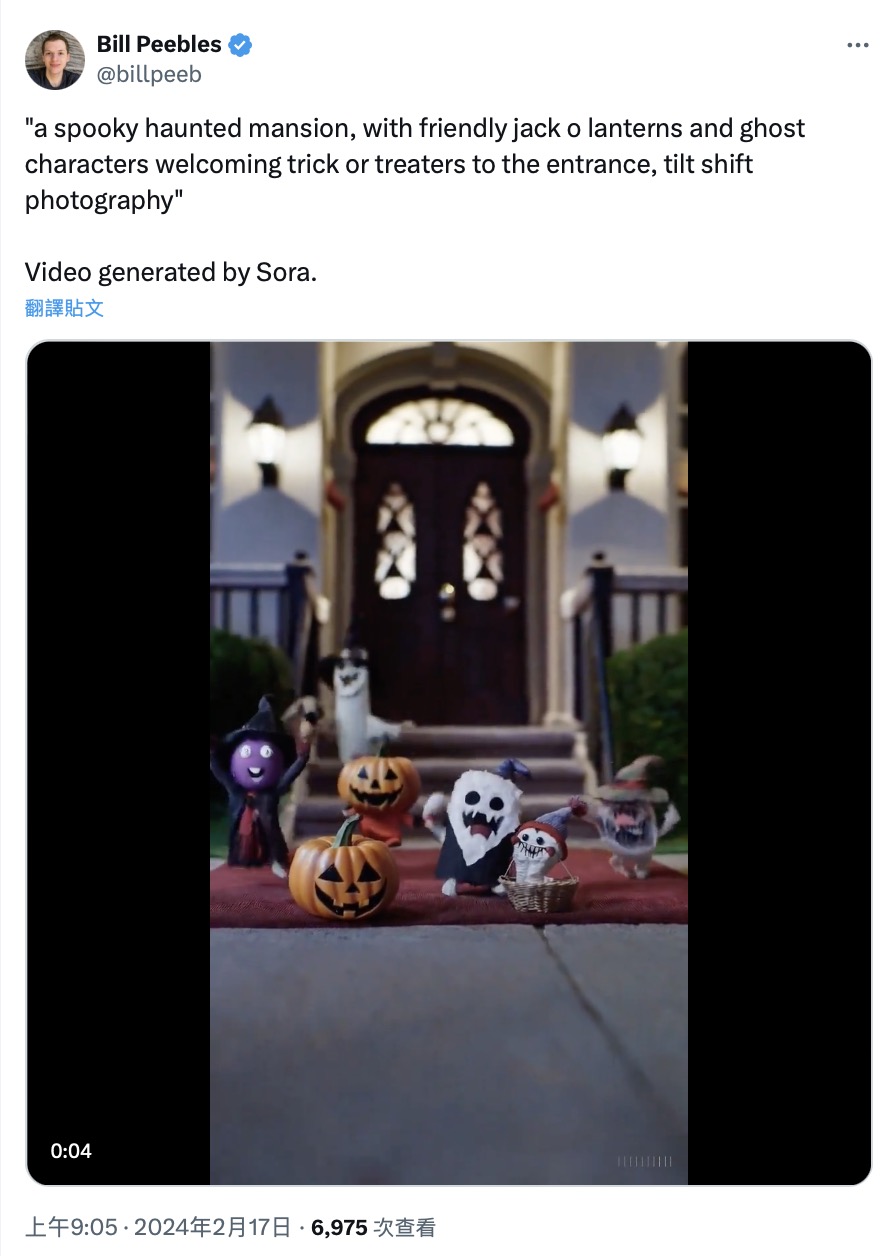
OpenAI的研究人员Bill Peebles在X上公布了几段视频和相应的提示词,比如这个“阴森恐怖的鬼屋,友好的杰克灯笼和幽灵人物在入口处欢迎捣蛋鬼,移轴摄影”,视频画面很好地呈现了描述词的内容。
知名科技YouTuber Evan Kirstel直接用“SORAWOOD”替换“HOLLYWOOD”的梗图表达对Sora的感叹。

NVIDIA科学家Jim Fan观察到一些针对Sora的质疑,包括那些认为Sora生成视频的过程只是在操作2D像素,对物理并没有真正的理解。他认为这样的观点过于片面,Sora 的软物理模拟是在大规模扩展文本到视频训练时产生的一种自然而然的特性。
Jim Fan在推文中分析称,GPT-4 必须内部学习某种语法、语义和数据结构,才能生成可执行的 Python 代码,Sora 也必须学习文本到三维图像、三维变换、光线追踪渲染和物理规则的隐性知识,这样它才能尽可能准确地模拟视频像素。它需要掌握游戏引擎的概念来达成这个目标。
如果不考虑交互性,虚幻5可以看作是一个生成视频像素的复杂过程。Sora 同样是一个生成视频像素的过程,但它是基于端到端的 Transformer 来实现的。这两者在抽象层面上是相同的。但不同之处是,UE5 是精心设计且精确的,而 Sora 则是完全通过数据学习和直觉来实现的。

不过Jim Fan也指出,Sora对物理的理解还很脆弱,远非完美,而且它还经常产生一些与我们常识不符的幻觉。它在理解物体互动方面还有很大的不足。
Sora 就像 GPT-3 的一个重要时刻。回顾 2020 年,GPT-3 尽管不够完善,需要大量的提示优化和监督,但它是第一个令人瞩目的在上下文中学习并展示出这种特性的模型,GPT-3固然有许多不足之处,但是想象一下,在不久的将来,GPT-4 将会带来怎样的变化。
在这些争论之外,已经有用户利用Sora“赚到钱了”,X平台上这位ID为“JamesGoong”的用户表示,他上线了一个sora app落地页,成交了一个年付。

从OpenAI官方公布的效果来看,和其他文字生成视频AI模型相比,Sora确实是令人印象深刻的进步。不过OpenAI自己也表示Sora还存在很多问题,可能难以准确模拟复杂场景的物理原理,也可能无法理解因果关系。
OpenAI 表示,他们还将与专家合作,找出模型的漏洞,并建立配套工具,来检测网上的视频是否由Sora 生成;同时还会与全球政策制定者、教育者、艺术家接触,来探讨如何不被滥用。
好文章,需要你的鼓励


AI智能体Sweekar:90年代电子宠物的现代继承者
在2026年CES展会上,一款名为Sweekar的AI电子宠物亮相,被誉为90年代经典Tamagotchi的完美继承者。这款智能宠物从蛋形开始,随着成长会物理性变大,经历婴儿期、青少年期到成年期的完整生命周期。每个阶段都有不同的护理需求和互动方式,从基础语言学习到形成独特个性。与原版相比,Sweekar融入了先进AI技术,提供更丰富的长期体验。该产品将通过Kickstarter众筹,售价150美元。

ETH苏黎世突破性WUSH技术:让AI大模型压缩实现接近零损失的革命性方案
瑞士ETH苏黎世联邦理工学院等机构联合开发的WUSH技术,首次从数学理论层面推导出AI大模型量化压缩的最优解。该技术能根据数据特征自适应调整压缩策略,相比传统方法减少60-70%的压缩损失,实现接近零损失的模型压缩,为大模型在普通设备上的高效部署开辟了新路径。

AI赋能农业:科技如何改造传统乡村世界
西班牙CTIC RuralTech创新中心运用AI等前沿技术解决农业面临的气候变化等重大挑战。通过气候模拟系统和土地使用智能分析,农户可以监测作物、预测不同种植条件下的结果,如同拥有时光机器。草莓生产商利用模拟器预测疾病影响和气候变化效应,奶酪制造商则用AI分析牛奶数据,确定最适合生产特定奶酪的原料。这些技术应用大幅提高了农业可持续性和效率。

机器人终于能读懂你的手势了!弗吉尼亚大学团队让机器人变身“人类动作翻译官“
弗吉尼亚大学团队创建了Refer360数据集,这是首个大规模记录真实环境中人机多模态交互的数据库,涵盖室内外场景,包含1400万交互样本。同时开发的MuRes智能模块能让机器人像人类一样理解语言、手势和眼神的组合信息,显著提升了现有AI模型的理解准确度,为未来智能机器人的广泛应用奠定了重要基础。
2024
02/17
13:15
分享
点赞

从十城抢租到场景落地,擎天租以创新租赁模式推动机器人普惠化
Proteintech选择亚马逊云科技为首选云服务商,构建行业首个AI抗体助手加速科研创新
大模型落地元年:AI Agent如何打破测试“效率墙”,重塑数智化质量基座?
从工具到团队:万智2.5多智能体正在改写企业决策与执行全链路
AI智能体Sweekar:90年代电子宠物的现代继承者
AI赋能农业:科技如何改造传统乡村世界
Disrupt创业大赛六大媒体娱乐初创企业盘点
OpenAI计划第一季度推出全新音频生成模型
Fizz社交应用CEO谈论匿名社交为何有效
Apple Health应用的强大功能及使用技巧大揭秘
VSCO Capture新增视频拍摄功能迎接新年到来
Instagram负责人:AI内容泛滥,为真实媒体加指纹比识别虚假内容更实用
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
