
зжНкЬјЖЏЙиБеСЫдкЗЧжоЕФWhatsAppЩНеЏЦЗ
зжНкЬјЖЏвбЙиБеLetsChatЃЌетПюдјБЛЪгЮЊWhatsAppКЭTelegramдкЗЧжоОКељЖдЪжЕФгІгУГЬађЁЃ
ИљОнЙйЭјЩЯЕФвЛдђЭЈжЊЃЌетМвзжНкЬјЖЏдк3дТ23ШеЭЃжЙСЫLetsChatЕФЗўЮёЁЃЭЈжЊжааДЕРЃК“вбЕЧТМЕФгУЛЇНЋЮоЗЈдйДЮЕЧТМЃЌЫљгаНБРјШЮЮёНЋЭЃжЙЃЌвбЭъГЩЕФШЮЮёНЋвдЛ§ЗжаЮЪНЗЂЗХЃЌЧыСєвтФњЧЎАќжаЕФгрЖюЁЃ” ЩљУїЛЙБэЪОЃЌLetsChatвбгк2дТ26ШеДгИїДѓгІгУЩЬЕъЯТМмЁЃ
Rest of WorldдЎв§зжНкЬјЖЏвЛЮЛЗЂбдШЫЕФгЪМўГЦЃЌЙЋЫООіЖЈЙиБеLetsChatдкФсШеРћбЧЕФдЫгЊЃЌвдзЈзЂгкЦфЫћгХЯШЪТЯюЁЃЗЂбдШЫЫЕЃК“дкзаЯИПМТЧКЭЦРЙРЮвУЧЕФеНТдвЕЮёФПБъКѓЃЌЮвУЧзіГіСЫетвЛОіЖЈЁЃЮвУЧИааЛLetsChatзїЮЊаэЖрИіШЫКЭЦѓвЕЕФживЊЭЈаХЙЄОпЃЌВЂИааЛЮвУЧгаЛњЛсЮЊФсШеРћбЧЕФгУЛЇЗўЮёЁЃ”
етвЛОіЖЈЃЌЪЧзжНкЬјЖЏЛЈСЫШ§ФъЪБМфЪдЭМШУLetsChatдкЗЧжоШЁЕУГЩЙІжЎКѓзіГіЕФЁЃЙЋЫОЭЈЙ§ЙЭгУЕБЕиЭХЖгВЂЭЖзЪЭЦЙуРДШУетПюгІгУГЬађЛёЕУИќИпжЊУћЖШЁЃЕЋзЈМвШЯЮЊЃЌетПюгІгУМИКѕУЛгаЛњЛсГЩЙІЃЌвђЮЊWhatsAppдкЗЧжоЕФЪмЛЖгГЬЖШМИКѕЮогыТзБШЁЃ
ФсШеРћбЧПЦММЗжЮіЪІBenjamin DadaБэЪОЃК“FacebookКЭWhatsAppЪЧФсШеРћбЧЁЂЗЧжозюДѓЪаГЁжаЪЙгУзюЖрЕФвЛаЉЦНЬЈЁЃЯёMetaетбљЕФОоЭЗЖрФъЧАОЭвбОЮЊетвЛЪаГЁСПЩэЖЈжЦСЫНтОіЗНАИ……Р§ШчFacebook LiteЃЌЙШИшвВгаYouTube GoЕШЁЃвђДЫЃЌШчЙћетЪЧЯћЗбепдкетаЉЪаГЁжавбОЪЙгУЕФФЌШЯбЁЯюЃЌФЧУДФњЕФ‘ЕЭЪ§Он’НтОіЗНАИФмгаЖрДѓЕФгХЪЦФиЃП”
зжНкЬјЖЏдк2021Фъ3дТЭЦГіСЫLetsChatЃЌжМдкЮЊФъЧсЕФЗЧжогУЛЇЬсЙЉвЛИіНкЪЁЪ§ОнЕФЯћЯЂЦНЬЈЁЃГ§СЫЖЬаХЃЌгУЛЇЛЙПЩвдУтЗбНјаагявєКЭЪгЦЕЭЈЛАЃЌВЂЧвПЩвдЭцгІгУФкЕФгЮЯЗЁЃвЛЮЛЧАдБЙЄЯђRest of WorldБэЪОЃЌзжНкЬјЖЏЙЭгЖСЫМИЮЛФсШеРћбЧЕФШЋжАКЭЖЬЦкКЯЭЌЙЄРДАяжњЭЦГіLetsChatЃЌЕЋвђБЃУмавщвЊЧѓФфУћЁЃ
зжНкЬјЖЏЛЙбћЧыСЫЯёAdebowale AdedayoЁЂChukwuebuka AmuzieКЭChinonso EgembaетбљЕФЗЧжожЊУћЩчНЛУНЬхгАЯьепРДЭЦЙуИУгІгУЁЃ
2022ФъЃЌLetsChatЕФЭХЖгЧАЭљФсШеРћбЧЕФбЇаЃЯђбЇЩњаћДЋИУгІгУЁЃзжНкЬјЖЏдкбЇаЃзщжЏСЫвЛЯЕСаЛюЖЏВЂЗЂЗХСЫЯжН№НБРјЁЃЫќЛЙЦєЖЏСЫвЛИіаЃдАДѓЪЙМЦЛЎЃЌдЪаэбЇЩњгыЙЋЫОУмЧаКЯзїЃЌВЂгЎШЁИќЖрЯжН№НБРјЁЃ
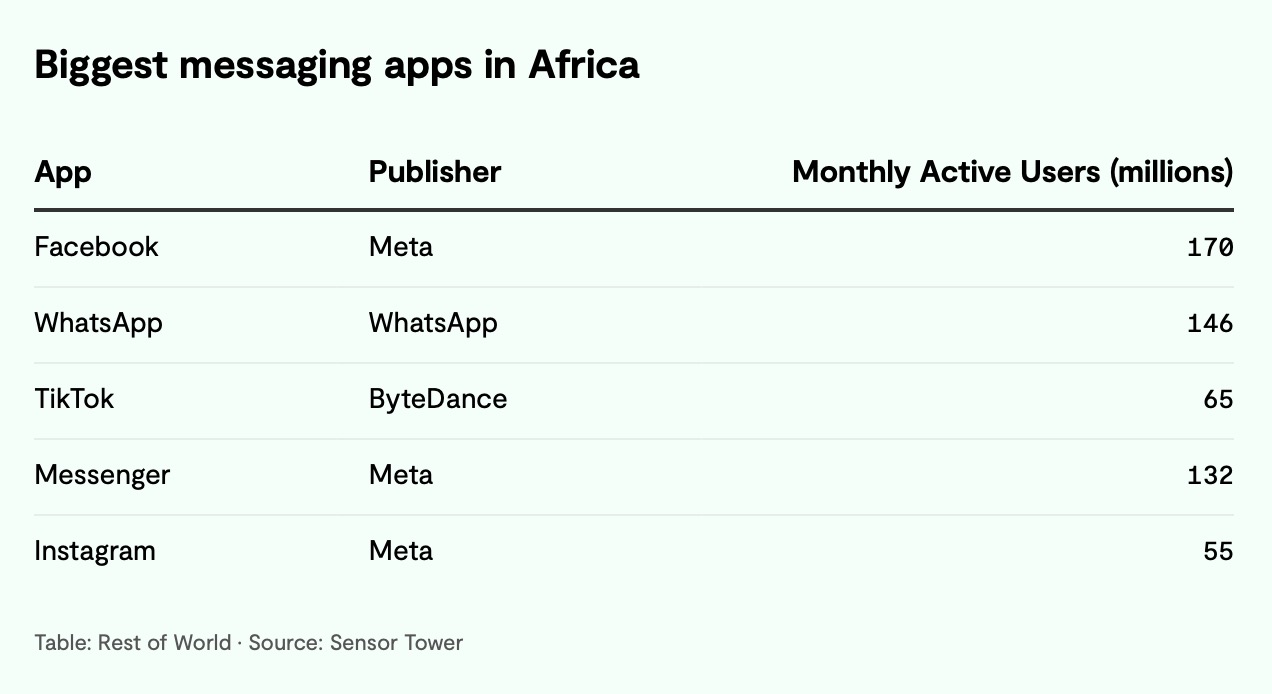
ОнЪаГЁЧщБЈЙЋЫОSensor TowerГЦЃЌЕН2023Фъ6дТЃЌLetsChatдкGoogle PlayЩЬЕъЕФЯТдиСПвбГЌЙ§500ЭђДЮЁЃЕНИУгІгУЙиБеЪБЃЌЦфЯТдиСПвбНгНќ700ЭђДЮЃЌЦфжа82%РДздФсШеРћбЧЁЃИУгІгУдкТэРяЁЂАВИчРКЭПЦЬиЕЯЭпвВгаДѓСПгУЛЇЁЃ
ОнSensor TowerГЦЃЌLetsChatЕФдТОљгУЛЇдк2021Фъ12дТДяЕНСЫдМ44ЭђЕФЗхжЕЁЃSensor TowerЕФбаОПгыЖДВьИБзмВУSeema ShahБэЪОЃЌгЩгкИУгІгУдк“ГДзїЭЦЖЏЕФЦєЖЏ”КѓФбвдЮЌГжЯћЗбепЕФаЫШЄЃЌ2022ФъЕФЯТдиСПЭЌБШЯТНЕСЫ30%ЁЃ
МДЪЙдк2023ФъЯТдиСПЩЯЩ§ЃЌLetsChatвВФбвдБЃГжгУЛЇВЮгыЖШЁЃ
ИљОнбаОПЙЋЫОSimilarWebЕФЪ§ОнЃЌдкЙ§ШЅЫФИідТжаЃЌИУгІгУЕФдТОљгУЛЇЪ§ГжајЯТНЕЁЃ2023Фъ12дТжС2024Фъ2дТЦкМфЃЌдТгУЛЇЪ§ЯТНЕСЫдМ33.4%——Дг125150ЯТНЕЕН83412ЁЃ
ShahБэЪОЃЌНижС2дТЃЌWhatsAppдкФсШеРћбЧЕФдТЛюдОгУЛЇЪ§СПЪЧLetsChatЕФ500БЖЁЃЫ§ЫЕЃК“WhatsAppДгЦфдкAppleЕФApp StoreКЭGoogleЕФPlay StoreЩЯГЌЙ§ЪЎФъЕФГЄЦкДцдкжаЪмвцЁЃ”
LetsChatВЛЪЧЮЈвЛвЛИіЪдЭМЬєеНWhatsAppдкЗЧжожїЕМЕиЮЛЕФЕЭЪ§ОнЯћЯЂгІгУЁЃдкФЯЗЧЃЌвЛПюУћЮЊMoyaЕФгІгУЬсЙЉУтЪ§ОнЯћЯЂЗўЮёЁЃЕЋDadaШЯЮЊетЛЙВЛЙЛЁЃ
DadaЫЕЃК“вЊЛїАмЯжгаЦѓвЕЃЌФуашвЊЫјЖЈЗжЯњ——FacebookКЭЙШИшЖМгыдЪМЩшБИжЦдьЩЬOEMНЈСЂСЫЧПДѓЕФКЯзїЛяАщЙиЯЕЃЌвдБуЫћУЧЕФЪжЛњдЄзАЦфгІгУЁЃгЩгкзжНкЬјЖЏЪЧРДздбЧЬЋЕиЧјЕФЙЋЫОЃЌИУЕиЧјгаСьЯШЕФOEMДЋвєЃЌШЫУЧБОЛсЦкЭћЫћУЧФмЙЛЯрЕБЧсЫЩЕиНЈСЂетбљЕФКЯзїЛяАщЙиЯЕЁЃ”
КУЮФеТЃЌашвЊФуЕФЙФРј


AIжЧФмЬхТЉЖДЭкОђГЩБОжшНЕЃЌAnthropicКєгѕAIЗРгљ
AnthropicЗЂВМSCONE-benchжЧФмКЯдМТЉЖДРћгУЛљзМВтЪдЃЌЦРЙРAIДњРэЗЂЯжКЭРћгУЧјПщСДжЧФмКЯдМШБЯнЕФФмСІЁЃбаОПЯдЪОClaude Opus 4.5ЕШФЃаЭПЩДгТЉЖДжаЛёЕУ460ЭђУРдЊЪевцЁЃВтЪд2849ИіКЯдМНіаш3476УРдЊГЩБОЃЌЗЂЯжСНИіСуШеТЉЖДВЂДДдь3694УРдЊРћШѓЁЃбаОПБэУїAIДњРэРћгУАВШЋТЉЖДЕФФмСІПьЫйЬсЩ§ЃЌУП1.3ИідТЗБЖдіГЄЃЌЧПЕїашвЊжїЖЏВЩгУAIЗРгљММЪѕгІЖдAIЙЅЛїЭўаВЁЃ

NVIDIAСЊЪжЖрЫљИпаЃЭЦГіSpaceToolsЃКAIЛњЦїШЫгаСЫЁАЛ№блН№ОІЁАКЭЁАУюЪжЛиДКЁА
NVIDIAСЊКЯЖрЫљИпаЃПЊЗЂЕФSpaceToolsЯЕЭГЭЈЙ§ЫЋжиНЛЛЅЧПЛЏбЇЯАЗНЗЈЃЌШУAIбЇЛсаЕїЪЙгУЖржжЪгОѕЙЄОпНјааИДдгПеМфЭЦРэЁЃИУЯЕЭГдкПеМфРэНтЛљзМВтЪджаДяЕНзюЯШНјадФмЃЌВЂдкецЪЕЛњЦїШЫВйзїжаЪЕЯж86%ГЩЙІТЪЃЌДњБэСЫAIДгЕЅвЛЙІФмЯђЙЄОпаЕїзЈМвЕФживЊзЊБфЃЌЮЊЮДРДИќжЧФмЪЕгУЕФAIжњЪжЕьЖЈЛљДЁЁЃ

SpotifyФъЖШХЬЕу2025ЪзДЮЭЦГіЖрШЫЛЅЖЏЙІФмЁАХЬЕуХЩЖдЁА
SpotifyФъЖШзмНсЙІФмЛиЙщЃЌдкШЅФъAIВЅПЭЙІФмдтгіХњЦРКѓЃЌНёФъжиаТзЈзЂгкгУЛЇЪ§ОнЩюЖШЗжЮіЁЃаТАцБОв§ШыНќЪЎЯюаТЙІФмЃЌАќРЈЪзИіЪЕЪБЖрШЫЛЅЖЏЬхбщ"Wrapped Party"ЃЌзюЖрПЩбћЧы9ЮЛКУгбБШНЯЬ§ИшЪ§ОнЁЃДЫЭтЛЙаТдіШШУХИшЧњВЅЗХДЮЪ§ЯдЪОЁЂЛЅЖЏИшЧњВтбщЁЂЬ§ИшФъСфЗжЮіКЭЬ§ИшОуРжВПЕШЙІФмЃЌШУФъЖШзмНсИќОпЛЅЖЏадКЭИіадЛЏЬхбщЁЃ

ЛњЦїШЫбЇЛсЁАШ§ЫМЖјКѓааЁАЃКжаПЦдКЭХЖгШУAIЛњЦїШЫИцБ№ааЖЏЪЇЮѓ
етЯюбаОПНтОіСЫЯжДњжЧФмЛњЦїШЫУцСйЕФ"ааЖЏВЛЮШЖЈ"ЮЪЬтЃЌПЊЗЂГіУћЮЊTACOЕФОіВпгХЛЏЯЕЭГЁЃИУЯЕЭГШУЛњЦїШЫдкжДааШЮЮёЧАЩњГЩЖрИіКђбЁЗНАИЃЌШЛКѓЭЈЙ§ЮБМЦЪ§ЙРМЦЦїбЁдёзюПЩППЕФааЖЏЃЌОЭЯёЮЊЛњЦїШЫХфБИжЧФмЙЫЮЪЁЃЪЕбщЯдЪОЃЌецЪЕЛЗОГжаЛњЦїШЫГЩЙІТЪЦНОљЬсЩ§16%ЃЌЧвЯЕЭГПЩМДВхМДгУЮоашжиаТбЕСЗЃЌЮЊЛњЦїШЫжЧФмЛЏЗЂеЙЬсЙЉСЫаТЫМТЗЁЃ
2024
05/16
17:58
ЗжЯэ
Еудо

СЊЯыШЋУцМЄЛюЪРНчБЙйЗНММЪѕКЯзїЛяАщЩэЗнЃЌЬььћAIзуЧђжЧФмЬхжиАѕЩЯЯп
AIВтЪдГЩЪ§жЧЛЏКЯЙцБибЁЯюЃЌЧ§ЖЏЦѓвЕИпжЪСПЗЂеЙ
AIжЧФмЬхТЉЖДЭкОђГЩБОжшНЕЃЌAnthropicКєгѕAIЗРгљ
SpotifyФъЖШХЬЕу2025ЪзДЮЭЦГіЖрШЫЛЅЖЏЙІФм"ХЬЕуХЩЖд"
гЂЙњSAPгУЛЇвђЩЬвЕЬзМўжиЦєЪкШЈУдОжИаЕНРЇЛѓ
AWSЗЂВМGraviton5ЖЈжЦCPUЃЌЮЊдЦЙЄзїИКдиДјРДЧПОЂадФм
УРЙтЗХЦњCrucialЦЗХЦЃКИцБ№ЯћЗбМЖДцДЂЪаГЁ
ЪжЛњРяЕФNPUдНРДдНЧПЃЌЮЊЪВУДAIЬхбщЛЙдкдЕиЬЄВНЃП
ШчКЮЪЙгУЯжгаЛљДЁЩшЪЉШУЪ§ОнзіКУAIзМБИ
ITСьЕМепПьЮЪПьД№ЃКЫМПЦЙтЭјТчЙЋЫОЪзЯЏЪ§зжаХЯЂЙйCraig WilliamsЗжЯэAIзЊаЭОбщ
Anthropic CEOОЏИцAIаавЕХнФЛЏЃЌХњЦР"YOLO"ЪНЭЖзЪ
бХЛЂРћгУAIЪЕЪБзмНсщЯщЧђБШШќОЋВЪФкШн
НќвЛАыУРЙњZЪРДњбЁдёжаЙњЕчЩЬЦНЬЈЙКТђНкШеРёЮя
БШбЧЕЯНјШыАЃШћЖэБШбЧЪаГЁЃЌЭЦГі 5 ПюЕчЖЏЦћГЕ
SheinдкФЋЮїИчЪаГЁЭЦГіЪзеХСЊУћаХгУПЈ
TikTokДЋДяЮДРДЗНЯђЃКГЄЪгЦЕЁЂИЖЗбЖЉдФКЭИпжЪСП
SheinМгЫйв§ШыШЋЧђЦЗХЦЃЌаТдіУРЙњЭЗВПЭЏзАЦЗХЦШызЄ
БШбЧЕЯГЌдНЬиЫЙРЃЌжаЙњЦћГЕвЕЕФШЋЧђЛЏеїЭО
Shein ЭЦГіЦЗХЦаХгУПЈЃЌВМОжН№ШкЩњЬЌ
ТэРДЮїбЧБОЭСЦћГЕЦЗХЦЕФЕчЖЏЛЏКРЖФЃКППАЎЙњЧщЛГФмЗёИЯБШбЧЕЯГЌЬиЫЙРЃП
SheinШЅФъдкЫќЕФЙЉгІСДжаЗЂЯжСЫСНЦ№ЭЏЙЄЪТМў
ПьЪБЩажЎеНЃКSHEIN гы Temu ЕФВаПсиЫЩБ
