
音视频全都要!Pika不再是单纯的视频生成工具 原创
给猫咪戴上墨镜、让麦田圈变成甜甜圈、在沙滩上显示你的名字…… 三言两语就能让AI生成一段视频,从早期的Runway到Pika,再到前阵子引起热议的Sora,每款产品出现,舆论都直指好莱坞,视频制作的门槛立刻被拉了下来。

其实Pika Labs的成立到现在也不过一年时间,去年11月29日,Pika 1.0发布时,宣传视频展现出惊艳的生成效果,只有4人的小团队,加上创始人是从斯坦福退学的两位年轻华裔女性,让Pika在当时变得极具话题性,也在中国引起热议。
不过Pika生成视频的效果至今没有什么进步,看起来也很难与Sora抗衡,所以目前Pika也只是更多地在功能和使用体验上下功夫。
在短短不到半年时间里,Pika增加了不少新功能,不仅能根据视频画面生成音效,还能为人物对口型,最近还推出了风格选项。Pika正试图把自己打造成一个“all in one”的视频制作工具,从画面到声音,一手包办。
Pika非常好上手,除了可以上传照片和视频外,使用方法基本和ChatGPT无异——输入你的指令,发送出去就行了。不过Pika比较麻烦的是,每次只能生成3秒钟的视频,如果想用Pika制作较长的视频,需要订阅它的几档付费计划,这样就能直接在上一次生成的3秒钟视频里接续生成后面的内容。
不过在生成完的视频下方点选“Add 4s”后的对话框界面,可以看出,它延长视频时间的方法,也只是在上一次生成的视频画面基础上,搭配提示词,而且也只能生成4秒钟而已。
所以我也可以截取生成完视频的最后一帧,配合提示词,让之前生成的故事延续3秒钟。
不过和许多生成式AI一样,Pika生成的内容也有一定的不可控性,想要最好的效果,不仅要精心设计提示词,也需要多多试错。
在修改视频的步骤上,Pika最近推出了修改风格(Styles)的选项,提供动漫、阴郁、3D、水彩、自然、粘土动画、黑白7种选择。
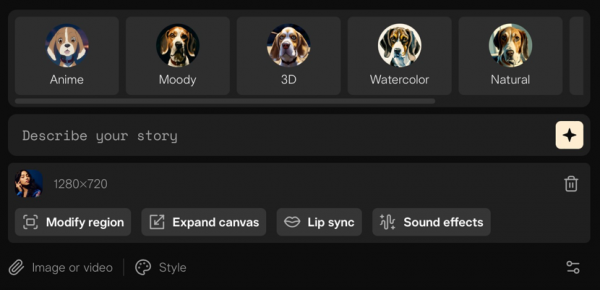
在实际选择一种风格后,就能看到一句提示词,说明这些改变风格的选项本质上还是通过输入提示词来实现的。
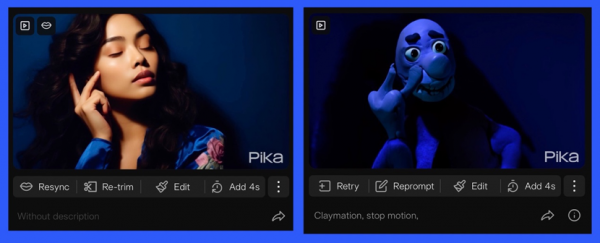
对比生成效果,构图虽然没有多大变化,风格夜的确是粘土动画,但整体的颜色还有任务的神态并没有很好的还原出来。
可能是为了弥补视频生成能力的不足,所以Pika一直在丰富自己的功能。前阵子还加入了音效(Sound Effects)生成能力,简单来说,就是让Pika识别视频内容,并搭配一段合适的音效。
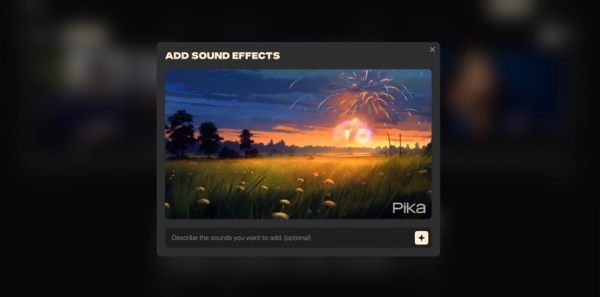
有时候Pika为视频生成的音效完全看不出与视频本身有任何关联性,所以Pika每次都会提供三种音效供选择,这也许也算是一种“补救措施”吧。
不过生成的音效到底能用,还是取决于视频内容,如果没有明显的场景,Pika可能也难以决定放怎样的音效比较适合。
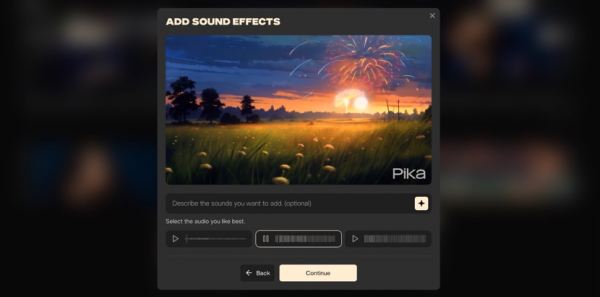
比如烟花的画面就比一间会议室或简单的人像更容易识别,你甚至不需要额外补充提示词,它就能生成完全符合画面内容的音效。
如果是人像画面,其实对口型(Lip sync)功能更适合它,只是这个功能与Pika的主要能力关联性不是很强,因为这个选项需要上传视频或照片,或者在生成好的视频里面点“编辑”按钮才能出现,而不是在文生图的过程中“顺便”完成一下。
可以输入文字,选择几个预设的声音,让他们帮你朗读,或者直接上传音频,根据音频内容对口型。
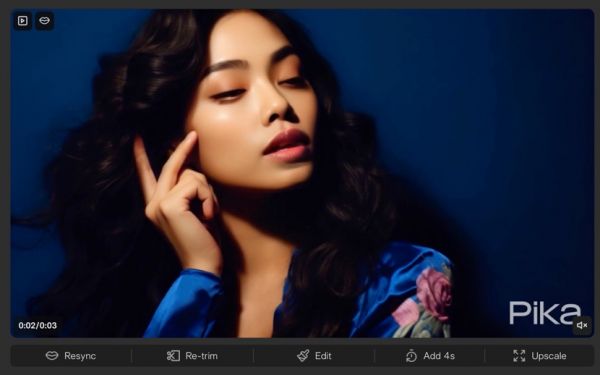
朗读的声音还是比较自然的,而且讲中文的语气也挺自然的,但问题是口型不太自然,能看得出是AI生成的。
Pika目前给我一种“泛而不精”的印象,什么功能都要沾一点,但表现都不尽如人意。也许现在的Pika定位娱乐体验多于生产力,从输入框旁边的骰子按钮就能看出这一点。
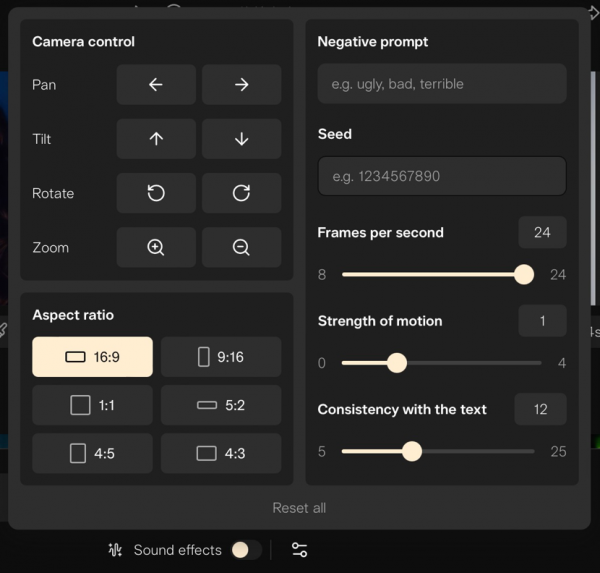
不过Pika也在丰富各种功能,而且每一项功能的使用体验都可以说相当精美,对于生成视频的画面比例、反向提示词、运动强度等等也有专门的区域做调整,甚至还提供了文件夹方便管理生成的项目,可以看出它在生产力上面也有十足的野心。
好文章,需要你的鼓励


谷歌将允许网站自主选择退出搜索AI模式与AI摘要功能
谷歌宣布将在Search Console中新增选项,允许网站发布者自主决定是否出现在AI Overviews、AI Mode及Discover中的AI摘要功能中。选择退出的网站将不再获得来自上述AI功能的流量和展示,但仍可正常出现在常规搜索结果中,且不影响搜索排名。此外,谷歌还将在Search Console中提供AI搜索相关数据统计,包括展示次数、出现页面及地区分布。该功能目前正在英国部分网站主中测试,后续将推广至全球。

当虚拟人物终于能“真实地打一拳“——来自耶路撒冷希伯来大学的4D人物动作仿真突破
耶路撒冷希伯来大学研究团队提出PhyGenHOI框架,将人体运动生成与物理仿真结合,让虚拟人物与三维物体之间的接触互动同时满足视觉自然性和物理真实性。

数据中心2026年6月最新建设动态
全球数据中心建设需求持续高涨。本月亮点包括:德克萨斯州超越北弗吉尼亚成为全球最大数据中心市场;SoftBank宣布在法国投资750亿欧元建设5GW数据中心;澳大利亚CDC数据中心签署该国史上最大555MW合同;东南亚方面,马来西亚、泰国大型AI数据中心项目密集落地。与此同时,多地在电网压力、环保审批及成本分摊等监管层面面临挑战。

弗莱堡大学等机构联合研究:让AI学会“立体思考“,彻底解决图像匹配中的左右不分难题
本文介绍了弗莱堡大学等机构提出的3D-SC框架,通过引入三维基础模型的几何先验,无需人工标注即可解决AI图像匹配中的左右混淆和重复部件分不清的问题。
2024
04/30
14:42
分享
点赞

谷歌将允许网站自主选择退出搜索AI模式与AI摘要功能
数据中心2026年6月最新建设动态
科技巨头IPO竞赛升温,OpenAI是否已错失良机?
氮化镓功率器件的技术进展与应用前景
JetPack 7.2:实体AI量产部署的关键时刻
DP World Tour首席技术官:用AI重塑高尔夫观赛体验
Perplexity推出混合AI架构,让个人电脑化身分布式数据中心
面向未来的配电系统需要具备哪些能力
重要提示:旧款Mac与iPhone将无法编辑Office文档
铜缆到了物理极限,光学替代不可逆,Scale-up域将有1000颗GPU:Marvell CEO在Computex做了一个预测
SAP 将收购 Prior Labs,在欧洲打造全球领先的前沿 AI 实验室
SAP 将收购 Dremio,以统一 SAP 与非 SAP 数据,赋能智能体 AI
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
