
小游戏即将登陆,能否拉高LinkedIn的人气?
作为微软旗下的社交平台,LinkedIn的核心亮点一直是帮助那些希望出于专业及招聘目的的用户们找到建立人际网络、获取知识的最佳场所。也正是凭借这个核心定位,LinkedIn业务目前已拥有超10亿用户。如今,为了增加该平台对于用户的粘性——即人们在平台上花费的时间,该公司决定进军一大全新领域——游戏。
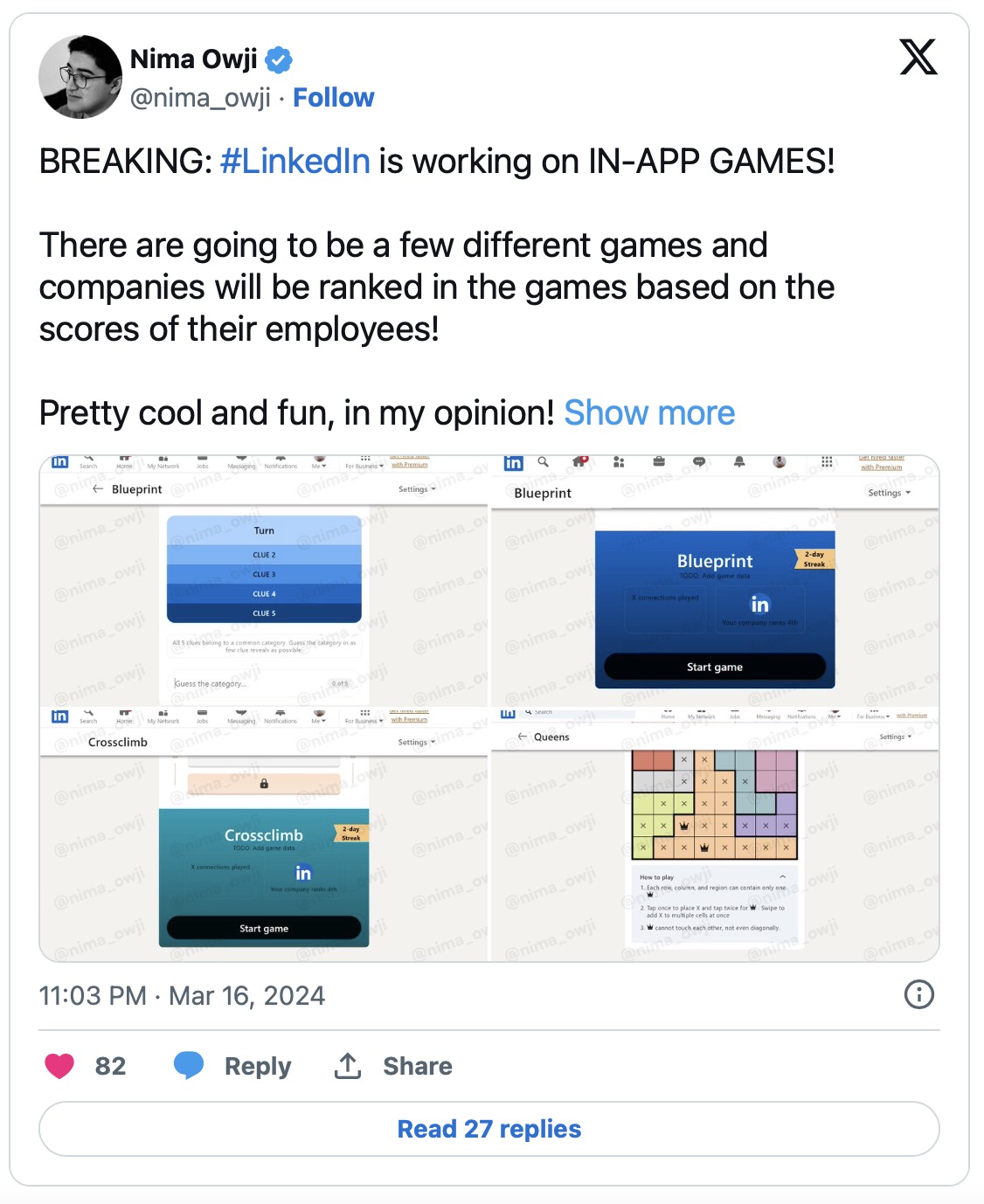
TechCrunch获悉并证实,LinkedIn正在开发新的游戏体验,希望通过轻松但又烧脑的解谜游戏达成这一用户粘性目标。其借鉴对象正是Wordle猜字游戏,事实证明这种简单的体验如病毒般传播并成功吸引到数百万玩家。LinkedIn选择的三款早期作品分别为《Queens》、《Inference》以及《Crossclimb》。
消息一出,众多应用研究人员立刻开始向LinkedIn的平台代码下手,想要剖析其中有哪些蛛丝马迹。一位名叫Nima Owji的研究者表示,LinkedIn似乎正在探索一种新方法,即按工作地点公布玩家得分排行榜,再根据这些分数对企业进行“排名”。
LinkedIn的一位发言人已证实该公司正在开发游戏产品,但强调尚未确定具体发布日期。
这位发言人向TechCrunch证实:“我们正尝试在LinkedIn体验中添加解谜类游戏以增添使用乐趣、加深关系并希望激发人们的社交热情。更多消息将稍后发布,敬请期待!”
这位发言人还补充称,研究人员在X上分享的截屏已经不是最新版本。
LinkedIn的母公司微软自己就是一家游戏巨头。其游戏业务包括Xbox、动视暴雪和ZeniMax,上季度收入达71亿美元,首次超过了Windows业务收入。
但LinkedIn公司发言人拒绝透露微软是否以及将如何参与LinkedIn的游戏项目。
无论是从收入还是用户参与度角度来看,游戏通常都是手机和PC平台上最受欢迎的应用软件之一,而基于解谜的休闲游戏一直是该领域最受移动用户青睐的类别。非游戏平台长期以来一直在利用这类产品为自己吸引流量——大家应该还记得当初报纸和杂志上随处可见的填字游戏或者有奖猜谜,可以说这种趋势早在互联网诞生之前就已经存在。
《纽约时报》于2022年收购了热门游戏Wordle,并在去年年底表示仍有数百万用户在持续享受这款游戏。该游戏现已成为《纽约时报》整体在线解谜与游戏平台的重要组成部分。
但其他着力投入游戏业务的企业却不一定能够收到预期中的效果。作为全球规模最大的社交网络,Facebook多年来一直是社交游戏业务的主要推动者。但在2022年,由于使用量下降,该公司决定关闭独立游戏应用;如今,他们开始将主要精力放在混合现实体验与Meta Quest业务身上。
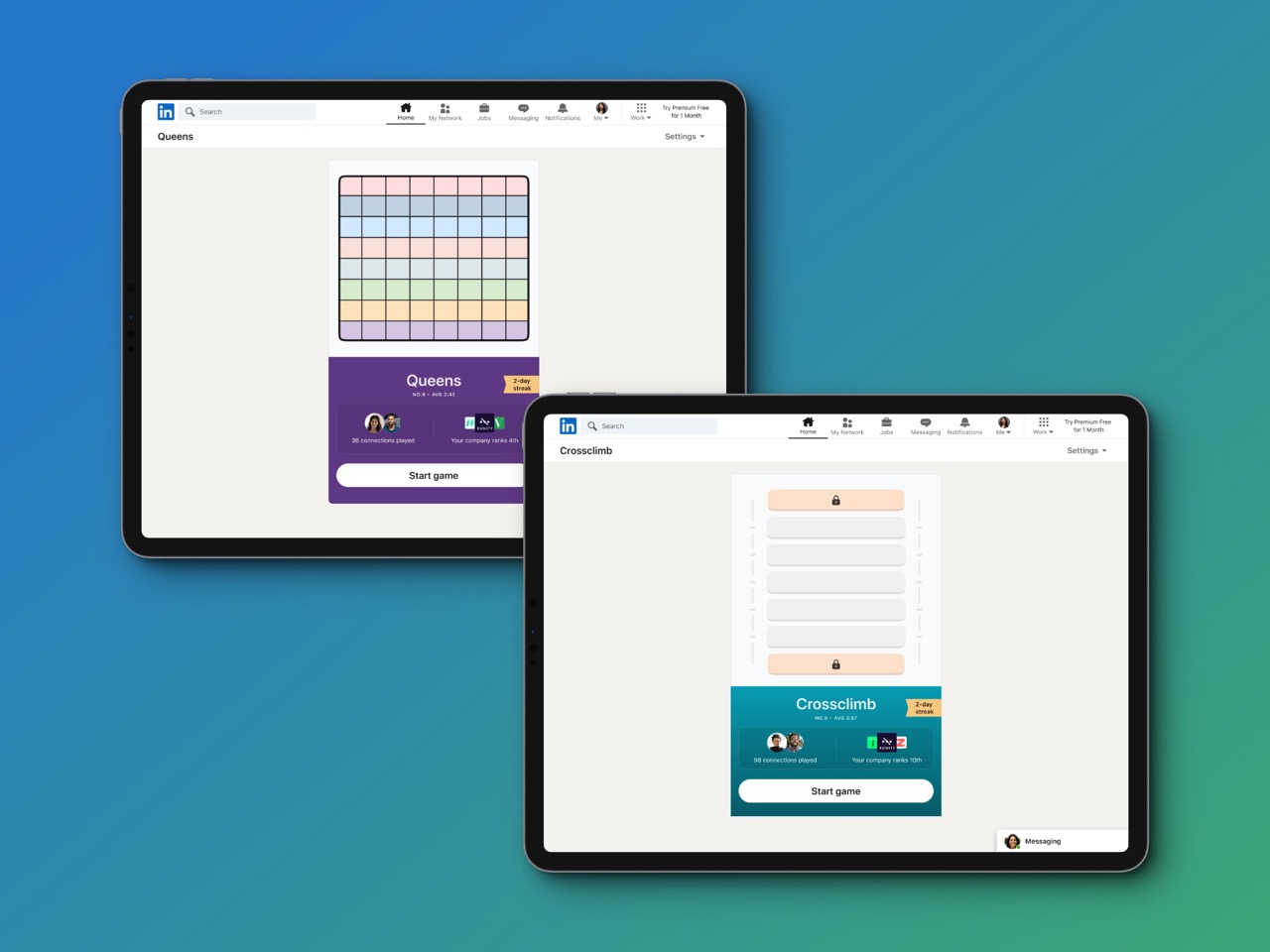
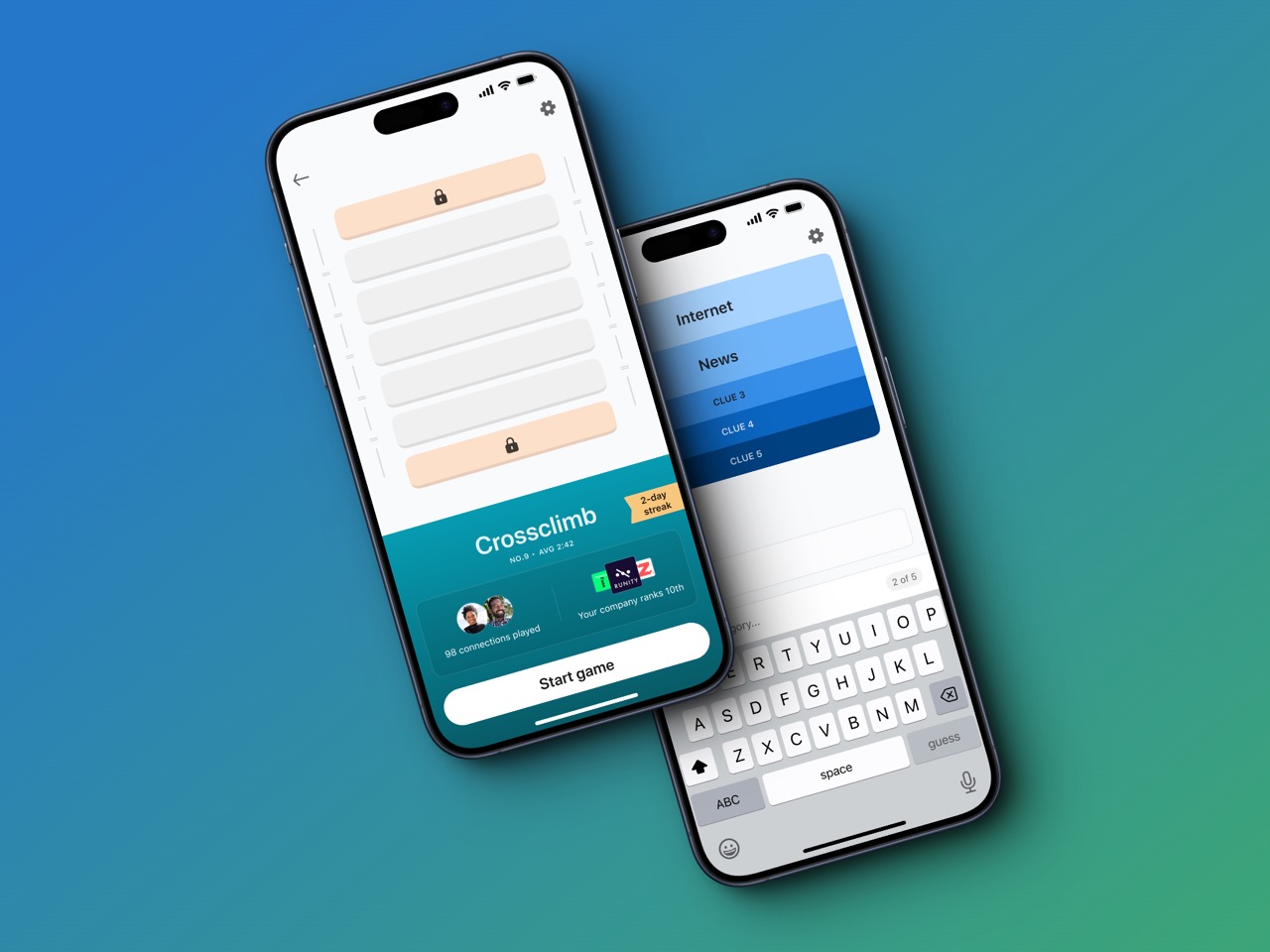
多年以来,LinkedIn也曾尝试过多种不同新功能,希望提高人们对该平台的粘性和参与度。所以对当前游戏策略的最佳总结,也许是“我们该如何利用人们最喜爱的流行工具,并将其与LinkedIn主体受众关联起来,从而在不分散职场这一焦点的前提下提高平台人气?”
之前的举措已经包括在线教育与职业培养、出版与新闻运营、引入更多视频工具以及招揽创作者与意见领袖等,这次引入游戏业务无疑是对LinkedIn整体战略的最新探索与合理延续。
好文章,需要你的鼓励


Inbolt将在Automate展会发布视觉驱动机器人编程新功能
机器人智能公司Inbolt将于2026年6月在芝加哥Automate展会上发布两项新能力:Inbolt机器人编程功能和扩展版机器人控制模块。新功能可让工程师直接基于CAD模型构建程序,结合视觉模型实时定位实体零件并自动调整运动路径,彻底消除传统调试中耗时数周的手动示教环节。此次更新还将原生支持安川机器人,使平台覆盖品牌扩展至六个。

当AI助手拥有“专属记忆“:Mind Lab用生物基因组类比,让数十亿人拥有自己的私人AI模型
Mind Lab提出三轴PEFT框架,通过增强共享基础模型、缩小个人适配器、扩展持久化适配器种群,探索百万个人AI模型的可行路径。

笔记本电脑深度清洁指南:内外兼修焕然一新
本文提供了一套完整的笔记本电脑深度清洁方案。硬件方面,介绍了如何用温和洗涤剂清洁机身、用微纤维布擦拭屏幕、用压缩空气清理键盘及清洁充电线的正确方法。软件方面,建议及时更新操作系统与驱动程序,删除冗余文件与临时下载内容,并通过开启Windows Storage Sense功能实现自动清理,同时将剩余文件整理归类,保持系统整洁高效运行。

韩国AI界的“高考难题“:当顶级AI遇上韩语网络搜索,为何集体“翻车“?——来自中央大学、KAIST、首尔国立大学等六所机构的联合研究
K-BROWSECOMP是一套专门测试AI在韩语网络中多步搜索推理能力的基准测试集,包含400道题,揭示全球顶尖AI模型在韩语环境下存在严重性能下滑,韩国本土模型得分更低至0%至10%。
2024
03/21
10:42
分享
点赞

AI驱动网络犯罪数量飙升,勒索软件受害者年增389%:Fortinet 发布2026年全球威胁态势研究报告
Inbolt将在Automate展会发布视觉驱动机器人编程新功能
笔记本电脑深度清洁指南:内外兼修焕然一新
加利福尼亚州城市通过全美首个由选民投票决定的数据中心禁令
柴油替代方案:AI数据中心如何利用燃气引擎与蒸汽涡轮供电
AI定义汽车时代,车载以太网可靠性面临全新挑战
安全算法的持续更新正变得愈发困难
轨道数据中心本质上是功能强化的卫星
Infineon Live Lab正式发布:全球首个实时云端实体硬件评估平台
Serve Robotics携手NoScrubs,自主配送机器人跨界拓展洗衣服务
Workr Robotics CEO:工业机器人自动化应按小时付费
专访CreateMe CEO:从缝纫到粘合,实体AI如何重塑服装制造
