
好莱坞告急!OpenAI发布Sora模型,瞬间生成高清大片 原创
OpenAI这两天发布一款名为“Sora”的视频生成AI,和许多视频生成工具一样,用户只要给出文字叙述或静态图片,Sora 就能自动生成 1080p 的动画,可以支持各种不同的角色、动作类型和背景画面。
“Sora”的名称源自日语的“天空”(そら),能够生成长达1分钟的视频,光是这一点就已经超越当前许多同类产品。OpenAI 已经向一些研究人员和创作者开放 Sora 的访问权限,OpenAI 在社交平台 X 发布的范例视频中,可以看到细腻的场景、复杂的运镜和情绪饱满的角色。

Sora 使用约10000 小时的”高品质“视频训练,OpenAI 表示,Sora 基于DALL·E、GPT 模型的研究成果,一方面使用DALL·E 3 的重述技术,能为视觉数据生成高度描述性的标题,所以Sora 可以更好地遵循用户的指令,生成情感丰富、引人入胜的角色,甚至还能深入理解指令提到的人、事、物在现实世界中的样子。
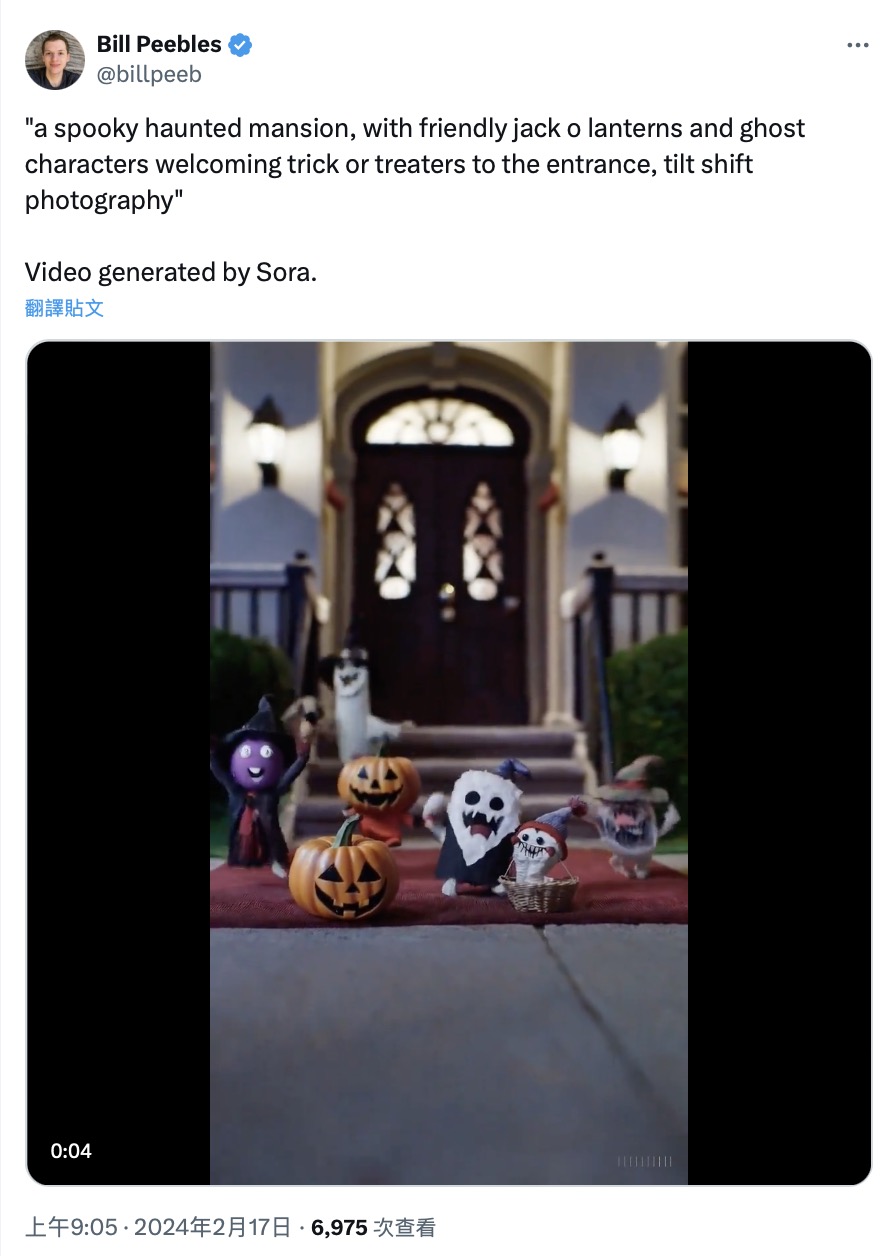
OpenAI的研究人员Bill Peebles在X上公布了几段视频和相应的提示词,比如这个“阴森恐怖的鬼屋,友好的杰克灯笼和幽灵人物在入口处欢迎捣蛋鬼,移轴摄影”,视频画面很好地呈现了描述词的内容。
知名科技YouTuber Evan Kirstel直接用“SORAWOOD”替换“HOLLYWOOD”的梗图表达对Sora的感叹。

NVIDIA科学家Jim Fan观察到一些针对Sora的质疑,包括那些认为Sora生成视频的过程只是在操作2D像素,对物理并没有真正的理解。他认为这样的观点过于片面,Sora 的软物理模拟是在大规模扩展文本到视频训练时产生的一种自然而然的特性。
Jim Fan在推文中分析称,GPT-4 必须内部学习某种语法、语义和数据结构,才能生成可执行的 Python 代码,Sora 也必须学习文本到三维图像、三维变换、光线追踪渲染和物理规则的隐性知识,这样它才能尽可能准确地模拟视频像素。它需要掌握游戏引擎的概念来达成这个目标。
如果不考虑交互性,虚幻5可以看作是一个生成视频像素的复杂过程。Sora 同样是一个生成视频像素的过程,但它是基于端到端的 Transformer 来实现的。这两者在抽象层面上是相同的。但不同之处是,UE5 是精心设计且精确的,而 Sora 则是完全通过数据学习和直觉来实现的。

不过Jim Fan也指出,Sora对物理的理解还很脆弱,远非完美,而且它还经常产生一些与我们常识不符的幻觉。它在理解物体互动方面还有很大的不足。
Sora 就像 GPT-3 的一个重要时刻。回顾 2020 年,GPT-3 尽管不够完善,需要大量的提示优化和监督,但它是第一个令人瞩目的在上下文中学习并展示出这种特性的模型,GPT-3固然有许多不足之处,但是想象一下,在不久的将来,GPT-4 将会带来怎样的变化。
在这些争论之外,已经有用户利用Sora“赚到钱了”,X平台上这位ID为“JamesGoong”的用户表示,他上线了一个sora app落地页,成交了一个年付。

从OpenAI官方公布的效果来看,和其他文字生成视频AI模型相比,Sora确实是令人印象深刻的进步。不过OpenAI自己也表示Sora还存在很多问题,可能难以准确模拟复杂场景的物理原理,也可能无法理解因果关系。
OpenAI 表示,他们还将与专家合作,找出模型的漏洞,并建立配套工具,来检测网上的视频是否由Sora 生成;同时还会与全球政策制定者、教育者、艺术家接触,来探讨如何不被滥用。
好文章,需要你的鼓励


Workday将Sana AI扩展至IT服务管理领域
Workday对话式AI平台Sana正式扩展至IT服务管理(ITSM)自动化领域,旨在帮助企业整合HR、财务与IT工作流程。新功能可自动处理员工入职/离职、权限变更及日常IT请求,同时新增"差旅助手"支持行程规划与费用管理。分析师指出,跨部门工作流统一将为CIO带来效率优势,但也警告需警惕供应商锁定风险,且在成熟ITSM市场中面临ServiceNow等强劲竞争。Sana ITSM功能预计2026年下半年开放早期使用。

纽约大学与Salesforce联手,让AI智能体学会了“执行规章“而非只是“接受建议“
HASP框架将AI智能体的技能经验从文字建议升级为可执行的程序函数,通过运行时自动触发干预而非被动建议,在网页搜索推理任务上相比强化学习基线提升30.4%。

风电场改造升级:行业迎来第二春
美国超过75,000台风力涡轮机正陆续迈入服役15至20年的生命周期末段,风电"翻新改造"(Repowering)正成为行业发展的核心战略。通过替换老旧组件或整机,结合现有基础设施、并网资源与土地权益,改造项目可显著提升年发电量、延长运营寿命并降低资本支出。文章从组件兼容性、选址条件、电网接入、环保审批及融资结构等维度,系统梳理了改造可行性评估的关键要素,为风电资产现代化提供决策参考。

神经网络训练中的“幽灵偏移“:斯科尔科沃科技大学团队揭开AI权重漂移的秘密
论文研究了神经网络训练中激活函数与损失函数的结构性交互导致的负权重漂移现象,分析了其引发激活稀疏性的机制,并探讨了稀疏度与模型性能的量化关系及优化激活函数的选择。
2024
02/17
13:15
分享
点赞

Workday将Sana AI扩展至IT服务管理领域
风电场改造升级:行业迎来第二春
三星49英寸超宽曲面电竞显示器降至史低价格
三星奥德赛G7和G8游戏显示器发布,附赠高达300美元积分及多款配件
量子计算初创公司Quantinuum申请上市
OpenRouter融资1.13亿美元,为企业AI推理路由带来新秩序
Modine 40亿美元协议:冷却产能变成预留基础设施
亚马逊物流竞争对手Stord融资2.5亿美元,估值达30亿美元
西北银行任命银行科技老将担任CIO
企业对智能体采用"一刀切"治理策略面临失败风险
我放弃ChatGPT,转用免费、私密的本地AI工具Ollama
三星Galaxy Tab S10 Lite降价100美元
最热门的 AI 模型:它们的功能和使用方法
这款古怪的 AI 智能手机可以创建你的数字分身
Faireez 获 750 万美元融资,为租赁市场提供 AI 驱动的酒店式管家服务
Broadcom 大获全胜:70% 大型 VMware 客户购买其最全面解决方案
Peer 获得1050万美元元宇宙引擎投资,推出3D个人星球功能
获 3000 万美元融资,Crogl 发布面向安全分析师的全新 AI "钢铁侠战衣"
Turing 获得 1.11 亿美元融资,估值达到 22 亿美元,为 OpenAI 等大语言模型公司提供关键代码支持
Tavus 推出系列 AI 模型,实现实时人脸交互技术突破
Welevel 获得 570 万美元融资,革新程序化游戏开发
AI 驱动的卓越运营:企业如何通过人人可及的流程智能提升成功
