
应用 | Dreamore:不止是一款用AI解读梦境的应用
Coco Chen是Dreamore的联合创始人,这是一个由Andreessen Horowitz的Speedrun支持的以人工智能为驱动的心灵健康平台。她曾在TikTok、Tinder和Uber工作。
Dreamore是一个应用程序,提供基于用户对自己梦境描述的人工智能生成的梦境分析和艺术作品。该平台还允许用户保持一个梦日记,并在匿名社区中讨论他们的梦境。
Coco Chen表示,新冠疫情期间,她在美国感到孤立无援,一些年长的家庭成员被困在国内。她经常经历强烈的梦境,并开始探索各种梦境分析方法:“这种探索导致我与我的联合创始人一起创造了Dreamore。我们在应用程序中整合了ChatGPT,让用户记录和解释梦境,并辅以独特的艺术作品。”
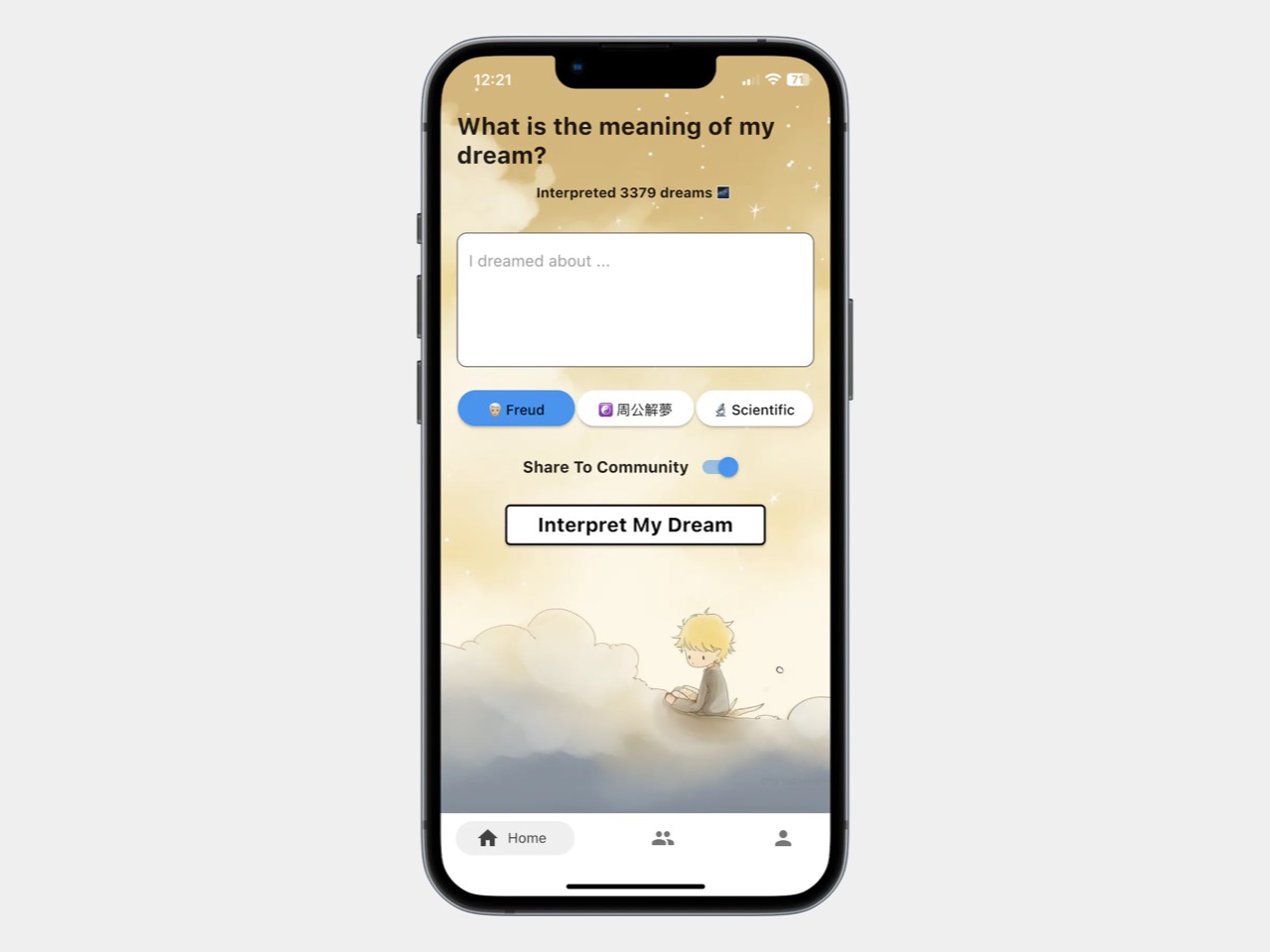
在Product Hunt上发布应用程序后,这款应用第一天就吸引了超过5000名用户,因为许多用户在应用程序中分享了他们的梦境。他们的调查显示,大量用户正在应对最近的创伤性生活事件,另外30%是频繁做梦的人,他们寻求更加了解自己。
她表示,虽然目前的梦境分析风格选项并不是临床心理治疗的替代品,但它们提供了对人类心理的宝贵见解。这些人工智能生成的见解,汲取了大量在线文献,为用户提供了一个探索他们的情感和精神状态的框架。这对于那些处于情感困扰中的人尤其重要,比如那些在乌克兰的用户,他们回忆战争和冲突的梦境。这款应用旨在成为他们情感疗愈旅程中的一个重要工具。
Coco Chen表示,在中国,类似的应用程序也有很多:“这样的心灵健康应用程序如Cece通常包含更广泛的功能范围,而美国的应用程序往往专注于特定功能。”虽然Dreamore目前集中在梦境上,但对探索借鉴中国应用程序的游戏化元素,以增强用户参与和留存也持开放态度。
好文章,需要你的鼓励


Glean年收入突破3亿美元,削减AI成本成核心卖点
企业AI搜索公司Glean宣布年度经常性收入(ARR)达3亿美元,较15个月前的1亿美元增长三倍。尽管谷歌、微软、OpenAI等科技巨头纷纷入局企业AI搜索市场,Glean凭借"上下文图谱"技术深度理解企业业务需求,并帮助客户显著降低AI计算成本。该公司提供按用量计费和混合定价两种模式,客户涵盖Databricks、Reddit、Pinterest及三星等企业。Glean上轮融资后估值达72亿美元。

香港中文大学与MiniMax联手破解AI图像描述的“说多错多、说少漏多“困局
香港中文大学与MiniMax提出ClaimDiff-RL框架,将图像描述的AI训练从整体打分升级为逐条核查,有效解决了传统方式导致AI"少说保平安"的问题,同时在多项基准测试上超越Gemini-3-Pro-Preview。

蓝色起源“新格伦“火箭在佛罗里达测试中发生爆炸
杰夫·贝索斯旗下的蓝色起源公司在佛罗里达卡纳维拉尔角进行静态点火测试时,新格伦重型火箭发生爆炸。这是美国历史上最大规模的火箭爆炸之一,也是蓝色起源公司遭遇的最严重失败。所有人员安全,但该事故可能导致新格伦火箭项目长期暂停。此前该火箭已成功完成三次发射,并实现了助推器回收和重复使用。

NTU、HKU等多所顶校联手,让AI同时“多角度看片“——视频理解的并行探针革命
ParaVT是一个由南洋理工等多校联合提出的并行视频工具调用框架,通过让AI同时分析多段视频并引入PARA-GRPO算法解决训练中的格式崩溃与工具跳过问题,在六项长视频理解测试中平均提升约7.9%。
2023
12/06
10:07
分享
点赞

Glean年收入突破3亿美元,削减AI成本成核心卖点
蓝色起源"新格伦"火箭在佛罗里达测试中发生爆炸
智能体AI正在重塑企业架构与Token经济学
堪培拉理工学院如何借助技术革新重塑课堂教学体验
Gemma 4携手Arm:优化端侧AI,加速移动应用体验
制药公司与初创企业如何携手推动AI落地
《星球大战》导演盛赞生成式AI:电影制作的革命性工具
Salesforce借助Informatica布局企业级无头数据管理架构
几乎所有M5 MacBook Air配置现在都降价近200美元
大模型评测风向变了,Testin云测如何构建企业级AI质量标尺?
因民事养老金管理失误,英国政府拒绝向Capita授予5.63亿英镑合同
YouTube提升AI生成视频标签的显示效果
