
Shopify 收购 Remix,后者维持独立开源框架身份
作为一家开发开源Web框架(类似于Next.js)的初创公司,Remix日前与Shopify发布联合声明,称已经被后者正式收购。虽然具体交易细节并未披露,但在一篇博客文章中,Remix公司CEO Michael Jackson表示,Remix将由此获得Shopify的“长期支持与助力”,帮助其“加快增长速度”并“专注于提升性能与可扩展性。”

Jackson表示,“未来,大家会看到越来越多的商业网站引入Remix框架。此外,Shopify本身也将在多个项目中使用Remix。随着时间推移,Shopify旗下也将地有更多开发者平台为Remix提供优先支持。”
Remix由Twitter前工程师Jackson及Ryan Florence于2020年共同创立。在决定推出Remix框架之前,两人已经投入多年围绕React(一款用于构建应用程序UI的JS库)创建开源工具。
Jackson与Florence最知名的开发成果之一就是React Router,这个React库迄今为止已经被下载近10亿次。事实上,Shopify最初就使用React Router来构建Hydrogen,即该公司用于构建自定义Shopify店面的前端Web开发框架。
至于Remix,这是一款全栈Web框架,在强调利用分布式系统和原生浏览器功能的同时,将后端服务器任务抽象出来。它能够与多种公有云环境相兼容,包括亚马逊云服务、Google Cloud、Netlify、Vercel以及Cloudflare Workers。作为一大核心功能,Remix的预取设计能够在用户实际点击之前并行预取网页元素,借此忽略链接上不必要的按钮和表单、实现最小化页面加载。
在被Shopify收购之前,Remix已经从OSS Capital和天使投资人Naval Ravikant、Ram Shriram及Sahil Lavingia处筹集到300万美元种子轮资金。
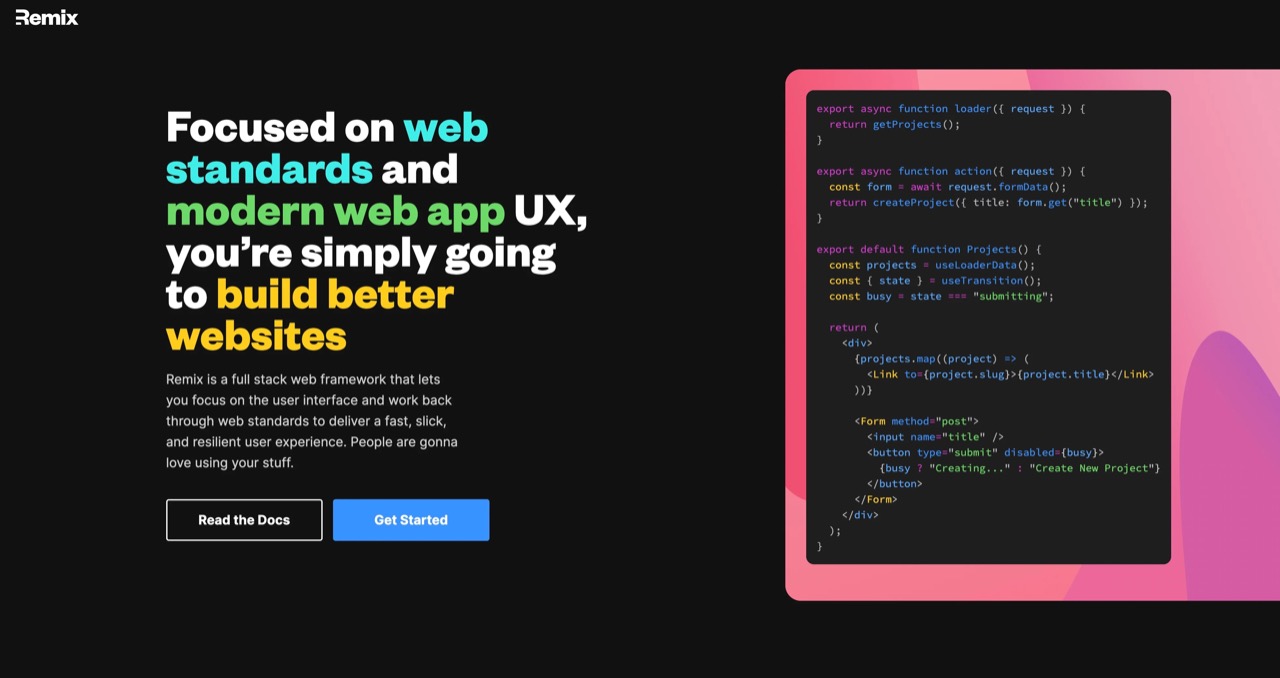
Shopify工程副总裁Dion Almaer在Shopify工程博客上的文章中表示,通过引入Hydrongen的种种改进要素,Shopify的开发者及商家都将从Remix收购案中获益。
Almaer表示:“Remix将继续保持独立的开源框架身份。Remix将帮助Hydrogen开发者们在数据加载、路由和错误处理上面临的挑战……Shopify将把Remix引入众多意义重大的项目,大家也将看到我们的开发者平台随时间推移为Remix提供优先支持。”
Remix是Shopify自今年5月以21亿美元收购配送技术提供商Deliverr之后的又一次交易。今年年初,Shopify还收购了专为品牌管理营销活动的Dovetail。而且继对CMS开发商Sanity和营销自动化初创公司Klaviyo做出股权承诺之后,Shopify最近还投资了Single——Shopify平台上一款广受好评的音乐和视频应用。
在经历艰难的第二季度之后,有迹象表明Shopify似乎已经度过了经济低迷期。该公司上周公布的第三季度亏损低于预期,好消息也使其股份当场飙升17%。
好文章,需要你的鼓励


Glean年收入突破3亿美元,削减AI成本成核心卖点
企业AI搜索公司Glean宣布年度经常性收入(ARR)达3亿美元,较15个月前的1亿美元增长三倍。尽管谷歌、微软、OpenAI等科技巨头纷纷入局企业AI搜索市场,Glean凭借"上下文图谱"技术深度理解企业业务需求,并帮助客户显著降低AI计算成本。该公司提供按用量计费和混合定价两种模式,客户涵盖Databricks、Reddit、Pinterest及三星等企业。Glean上轮融资后估值达72亿美元。

香港中文大学与MiniMax联手破解AI图像描述的“说多错多、说少漏多“困局
香港中文大学与MiniMax提出ClaimDiff-RL框架,将图像描述的AI训练从整体打分升级为逐条核查,有效解决了传统方式导致AI"少说保平安"的问题,同时在多项基准测试上超越Gemini-3-Pro-Preview。

蓝色起源“新格伦“火箭在佛罗里达测试中发生爆炸
杰夫·贝索斯旗下的蓝色起源公司在佛罗里达卡纳维拉尔角进行静态点火测试时,新格伦重型火箭发生爆炸。这是美国历史上最大规模的火箭爆炸之一,也是蓝色起源公司遭遇的最严重失败。所有人员安全,但该事故可能导致新格伦火箭项目长期暂停。此前该火箭已成功完成三次发射,并实现了助推器回收和重复使用。

NTU、HKU等多所顶校联手,让AI同时“多角度看片“——视频理解的并行探针革命
ParaVT是一个由南洋理工等多校联合提出的并行视频工具调用框架,通过让AI同时分析多段视频并引入PARA-GRPO算法解决训练中的格式崩溃与工具跳过问题,在六项长视频理解测试中平均提升约7.9%。
2022
11/02
09:32
分享
点赞

Glean年收入突破3亿美元,削减AI成本成核心卖点
蓝色起源"新格伦"火箭在佛罗里达测试中发生爆炸
智能体AI正在重塑企业架构与Token经济学
堪培拉理工学院如何借助技术革新重塑课堂教学体验
Gemma 4携手Arm:优化端侧AI,加速移动应用体验
制药公司与初创企业如何携手推动AI落地
《星球大战》导演盛赞生成式AI:电影制作的革命性工具
Salesforce借助Informatica布局企业级无头数据管理架构
几乎所有M5 MacBook Air配置现在都降价近200美元
企业用好Agent,关键不在“买一个智能体”|原点Talk 分享会
大模型评测风向变了,Testin云测如何构建企业级AI质量标尺?
因民事养老金管理失误,英国政府拒绝向Capita授予5.63亿英镑合同
