
AMD发布CDNA架构Instinct MI100加速显卡 加速百亿亿次级时代到来
11月16日晚10点,AMD正式发布了首款基于全新CDNA架构的Instinct MI100加速显卡,以及配套的ROCm 4.0生态系统。

首次正式亮相的CDNA架构专门为高性能计算所打造,而基于该架构的AMD Instinct MI100加速显卡将进一步逼近百亿亿次级计算时代,同时也是AMD向前方开拓新发展路径的新旗舰产品。

AMD高级副总裁兼服务器业务总经理Dan McNamara表示,在高性能计算方面,整个行业发展十分迅速。我们看到的趋势是,工作负载的多样性在不断增加,高性能计算已经进入到很多领域,包括从传统科研,气象研究,生命科学,电子设计自动化到商业应用,从AI、机器学习到算法培训等等,如何通过CPU和GPU方面的组合更好地服务于客户、为客户带来更多单位成本性能和减少总体拥有成本,将是AMD极其重要的战略之一。

不过最令用户之间关心的,相信还是本次发布的新品加速显卡。AMD平台解决方案工程研发全球副总裁Brad Mccredie对此进行了全面解读。
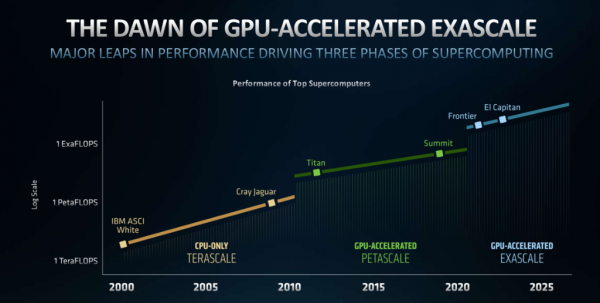
在整个过去20年里,整个高性能计算经历了三个阶段,分别是TERASCALE、PETASCALE和现在的EXASCALE。在这个过程中我们需要一系列技术来支持EXASCALE这样一个百亿亿次级计算。
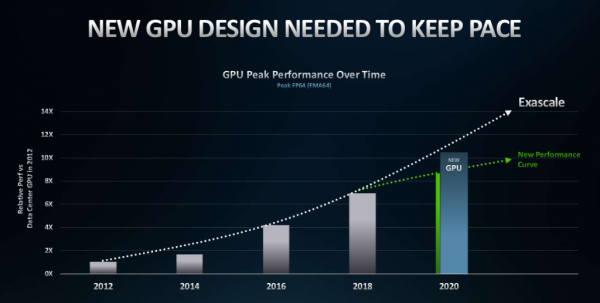
作为一款针对高性能计算而专门设计的行业领先GPU产品,AMD Instinct MI100旨在为推动百亿亿次级计算时代到来,能够实现10TF(十万亿次双精度计算速度),具备Matrix核心技术。与AMD上一代产品相比有着巨大的性能提升,能够实现高达70%的AI计算加强;而与竞争对手相比,在每单位性能上也是对方的两倍。特别是在搭配第二代AMD EPYC处理器使用时,还可为系统提供更强的加速性能。

20年前ASCI White超级计算机进入超算领域,并率先突破10TF关卡。20年之后,现在单个GPU仅在6兆瓦的性能上就可实现这样一个性能水平,这就是AMD Instinct MI100加速显卡,可以说这就是20年后非常巨大的成就之一。

目前市面上的大部分GPU采用的都是通用架构,这意味着这个架构既用于游戏图形处理,也用于复杂数学方面的处理,实际上很大的制约了向百亿亿次级计算的发展。而AMD选择将这两部分分离,为我们已经所熟知的针对游戏行业的RDNA架构,以及针对超算计算的CDNA架构。这样的分离可以帮助相关人员进一步针对领域内的工作负载进行优化。

以AMD Instinct MI100为例,CDNA架构可在同一晶片上放入了两倍数量的计算单元,并可以嵌入微架构以更好的适应AI和高性能计算的工作负载。同时在16位浮点计算和混合精度计算方面也能实现7倍以上的性能提升,另外通过Infinity架构还可以将GPU的带宽提升4倍、通过HBM2内存来实现20%的位宽提升。
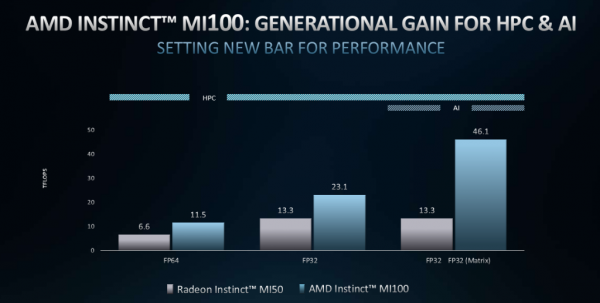
上文中多次提到的AMD Instinct MI100加速显卡正在进一步逼近百亿亿次级计算时代,而AMD Instinct MI100的双精度计算性能可以达到11.5TF的水平,单精度计算水平会更高。

据介绍,橡树岭国家实验室就通过使用MI100来进行相关工作负载,在分子动力学负载中,与v100加速显卡相比速度提升3倍。而在Fluid Turbulence的工作负载中,也比v100加速显卡有2.6倍的速度优势。作为早期客户使用的效果来看,这一数据十分具有说服力。

另外,AMD还强调既要有世界级硬件,也需要世界级生态来做配套。为此,还推出搭配使用的开源软件站ROCm 4.0,为百亿亿次级计算提供了新基础。

该平台不仅相较上两代产品,可实现MI100高达5-8倍的性能提升,还可为开发者们提供简单快捷的代码迁移功能,甚至最短1天就可完成某些代码的迁移工作。

自代号为“罗马”的第二代霄龙处理器发布以来,AMD在服务器市场便收获了不俗的成绩,时至今日它仍是市面上行业领先的x86服务器。根据Intersect360此前的调查显示,从16年至今,用户对霄龙处理器的前瞻性印象和好感度增加了两倍之多。
如今,AMD在MI100加速显卡和ROCm 4.0开源平台的推出后,除了进一步完善AMD在服务器市场的产品布局外,相信也定将会为客户们带来更为优越的HPC工作基础,推动百亿亿次级时代抢先到来!
来源:至顶网商用办公频道
好文章,需要你的鼓励


苹果在印度恢复银行卡支付功能,距暂停已逾四年
苹果已开始在印度分阶段恢复Apple账户的信用卡支付功能,用户可绑定Visa和Mastercard信用卡及借记卡,用于购买iCloud+、Apple Music订阅及App Store应用。此前,由于印度储备银行于2021年推出新的周期性支付监管框架,苹果于2022年5月暂停了该支付方式。此次恢复标志着苹果在适应各国本地化监管要求方面的持续努力,同时也引发外界对苹果是否将在印度推出Apple Pay的新猜测。

腾讯混元团队打破AI“记忆瓶颈“:让大模型像人一样拥有超长记忆的新突破
腾讯混元等机构提出HiLS-Attention,通过端到端可学习的分层稀疏注意力机制,让大模型在超长上下文推理中比全量注意力快14倍,同时检索准确率更高。

Bookshop.org确认今年将推出Kobo电子书阅读器支持
Bookshop.org创始人Andy Hunter证实,与Kobo的合作集成将于今年落地。此前该计划历经多次推迟,网页措辞一度从"2026年"改为"未来某时"。Hunter表示,双方已就商业条款达成一致,工程团队正将资源重新投入Kobo支持开发,但尚无具体上线日期。该集成将支持数字版权管理要求,让用户通过Bookshop.org购买电子书,同时支持独立书店。

DeepSeek-AI与北京大学联手破局:AI聊天机器人“慢速打字“的终极解决方案
DSpark是DeepSeek与北京大学提出的投机解码框架,通过半自回归生成和置信度调度验证两项创新,将DeepSeek-V4用户生成速度提升60%至85%。
2020
11/17
10:07
分享
点赞

苹果在印度恢复银行卡支付功能,距暂停已逾四年
Bookshop.org确认今年将推出Kobo电子书阅读器支持
WeWard新增"步行模式":走够步数才能解锁应用
X将通过私信通知用户其互动帖子被社区笔记纠错
"慢社交"应用Roost:让消息像真鸟一样飞行
Truecaller与印度电信监管机构就反垃圾电话规则展开公开交锋
Block与46州达成4500万美元和解,涉Cash App欺诈纠纷
欧盟威胁对Meta开出罚款,剑指Facebook和Instagram上瘾性设计
Disney+考虑推出免费流媒体内容层级
HyperTexting:将开放网络变成类社交媒体信息流的新应用
TV Time关闭之际,创始人打造新追剧应用Bingers
Telegram短链域名t.me因制裁合规问题短暂下线后已恢复
AMD 发布新一代 AMD RDNA(TM) 4 架构,推出 AMD Radeon(TM) RX 9000 系列显卡
苏姿丰的十年历程回顾:AMD如何从英特尔廉价替代品成长为x86领域的有力竞争者
面临AMD及自身内部挑战,英伟达Green 500主导地位受到威胁
微软率先拿下HBM驱动的AMD CPU供货
基于 AMD 加速器的 El Capitan 首次登全球超算500强榜首
突发!AMD大爆雷!
AMD Versal家族再添新成员 ——打破AI内存桎梏 支持CXL 3.1
AMD超低时延金融加速卡 帮你跑赢高频交易“竞速赛”!
要超越英伟达,AMD还须十年时间
深度剖析:聊聊英特尔与AMD各自不同的CPU整合思路
