
赛普拉斯IoT战略解读:加强产品自身,更做垂直领域的应用 原创
至顶网商用办公频道 05月11日 北京消息(文/黄当当):互联网实现了计算机的联网,而要实现万物互联则需要物联网。但物联网的开发并非一蹴而就,有没有一条捷径可走?

这是赛普拉斯半导体公司一直在做的事。面向物联网开发者,赛普拉斯拿出一套名为「IoT-AdvantEdge」的解决方案,囊括了连接芯片、微控制器(MCU)、软件、开发工具等,旨在通过解决一系列关键物联网设备的设计问题,降低开发的复杂性。
从命名上看,这套方案是面向物联网边缘,助力客户更快将产品推向市场。它包括了经预先认证的各种方案,整合了包括无线连接、云安全、设备管理和维护、中间件和低功耗芯片等物联网基本构建模块,覆盖了数据共享,隐私,环境感知,实时控制,连接等5个维度的边缘计算所需。
IoT战略解读,坚持“两条腿”走路
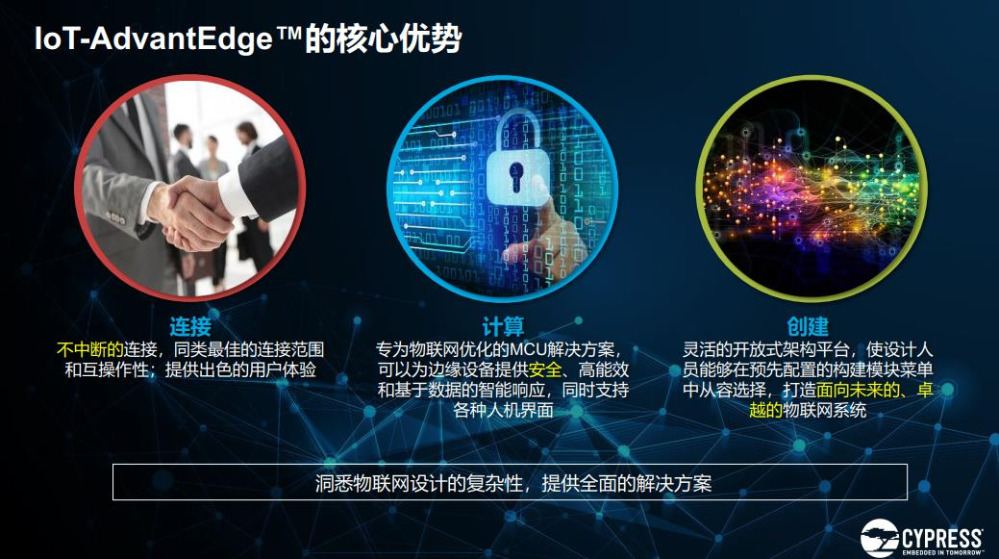
赛普拉斯物联网微控制器及无线事业部高级市场总监Amy Chen表示,IoT-AdvantEdge的核心优势体现在连接、计算、创建这三个层面,未来还会围绕这些优势做一些垂直领域的芯片,两条腿走路,一方面加强本身产品,另一方面去各式各样的垂直应用。目前包括 PSoC 6系列、PSoC 4系列,其实赛普拉斯有更多、更新的产品丰富在整个系列当中。
但半导体和芯片设计始终是一个复杂的课题,现在国内有很多创新的MUC厂商,利用MCU+AI概念深耕垂直领域,对此Amy Chen认为,如果能真正深入到用户的应用场景和需求层面,抓住用户的痛点,并在垂直领域做针对性的加速引擎,未尝不是一个好的方向,而赛普拉斯希望是面向垂直领域应用的芯片。
“ 我们沉下心来做事有两三年的时间了,我们在各个垂直领域有很多的深入探索,包括大家看到的PSoC 65,包括在智能门锁领域,包括HID、IP camera、Doorbell、打印机等各方面。”Amy Chen说道,她期望的目标是赛普拉斯能做物联网行业的领头羊,不仅要有广泛的产品线覆盖物联网市场,而且对某些垂直行业要有深刻的理解。
突破关键,IoT-AdvantEdge方案全解析
事实上,IoT-AdvantEdge平台解决方案正是集聚了大智慧,是团队经过多年的行业积累,与行业客户一同合作打磨出来的。围绕IoT-AdvantEdge方案,Amy Chen还做了以下详细解读:
- 芯片:赛普拉斯拥有独特的微控制器(MCU)、Wi-Fi、经典蓝牙(Classic Bluetooth)/低功耗蓝牙(BLE) 组合,它们可以协同工作,支持从电池供电的摄像头到医疗产品的各类物联网设备需求。此外,它们还集成了软硬件安全和强大的通信技术,被应用在众多最精密的物联网产品中。
- 软件:强大的软件是构建高质量、安全和可靠产品的基础。赛普拉斯的软件专为物联网而打造。 ModusToolbox开发工具链与 PSoC 等 RTOS微控制器(MCU)相配合,极大地简化了Wi-Fi和蓝牙(BT/BLE)类物联网产品的开发。 ModusToolbox 的中间件能够助力企业将其产品连接到领先的云软件平台,或者公有/私有云基础架构上的专有云服务。
- 开发工具与支持:赛普拉斯的开发工具包括了低功耗助手、多RF射频协同共存、安全认证和 OTA 升级,能显著减少将高质量产品推向市场所需的时间和成本。 Cirrent(赛普拉斯的子公司)提供的基于云的分析平台“物联网网络智能(INI)”,可以为物联网产品提供连接、网络和其他产品性能参数方面的前所未有的洞察力。
- 生态伙伴的协力:打造物联网产品通常需要广泛的供应链生态的协作。赛普拉斯预先集成了来自云服务提供商、特定用途的半导体产品、应用开发者等众多生态伙伴的服务,以帮助企业更快地将其物联网产品推向市场。

作为 IoT-AdvantEdge 发布活动的一部分,赛普拉斯同时推出了许多新的物联网产品和资源,包括:
- 全新的微控制器(MCU):赛普拉斯的 PSoC 6 MCU 系列产品中加入了两个全新的配置,即:为 PSoC 62 MCU 和 PSoC 64 Secure MCU 产品线提供新的内存选择。其中,一款拥有高性能、M4F/M0 双核架构, 2MB Flash和 1MB SRAM;另一款则性价比更高,拥有 512KB Flash和 256KB SRAM。两款全新的配置让企业能够更加灵活地为物联网应用选择合适的配置。
- 全新的开发套件:全新的开发套件包含多种低功耗解决方案,能够帮助设计人员解决复杂的连接、安全部署、安全固件管理和云安全等问题。这些集成的解决方案由 ModusToolbox 软件提供支持,并已通过 AWS IoT Core 和 Pelion™ 云应用的验证,能够简化家庭自动化和便携式消费类设备的开发。
- PSoC 62 2M 43012 Pioneer 套件:超低功率的M4/M0+ MCU,支持双频2.4G/5G IEEE 802.11n Wi-Fi 和 Bluetooth® 5.0.
- PSoC 62 512K 4343W 原型开发套件:高性价比的人机交互 MCU,支持 IEEE 802.11n Wi-Fi 和 Bluetooth 5.0
- PSoC 64 2M Secure Boot 4343W Pioneer 套件:安全的云连接和配置,安全的固件管理
- Cypress-Azurewave 模组先锋套件:已经通过无线认证的模组,提供一个“交钥匙”的互联 MCU 平台方案,可以轻松集成于任何物联网产品
- 全新的软件:ModusToolbox将赛普拉斯安全计算和连接领域的专业实力整合到一个通用的软件工具当中,使物联网开发人员能够更容易将成功的产品推向市场,并在整个生命周期中提供支持。本次,赛普拉斯发布了 ModusToolbox 2.1 版本,该版本将扩展到 AWS IoT Core 和 Pelion 服务以外的云服务支持,以覆盖那些已自行构建云后端的客户。如今,ModusToolbox 已支持五个常用的 IDE,开发人员可以选择他们偏好的开发环境。
- 全新的线上资源:赛普拉斯在Cypress.com上推出了IoT-AdvantEdge,并为开发者社区设立了专门的物联网开发者专区。 赛普拉斯开发者社区为全球的访客提供了专业的技术论坛、技术博客和资源库。赛普拉斯开发者社区还致力于为客户、开发者和合作伙伴搭建沟通的桥梁,方便大家获取海量资源,最终将高质量,安全和可靠的产品更快推向市场。
对于IoT-AdvantEdge解决方案,赛普拉斯总裁兼首席执行官 Hassane El-Khoury也充满信心,他表示:“打造智能、互联的物联网边缘计算产品极具挑战性。既要让无线连接和嵌入式系统协同工作,同时还要处理好系统安全、云集成和能效管理等问题,这些都需要消耗大量时间和成本。赛普拉斯致力于解决大家所遇到的难题,我们将直面这一挑战,不断壮大我们的解决方案,支持企业更快地将高品质、安全、可靠的产品推向市场。”
来源:至顶网商用办公频道
好文章,需要你的鼓励



AI助手越权了?南加州大学等机构揭示大模型代理的“权限失控“问题
FORTIS是专门测量AI代理"越权行为"的基准测试,研究发现十款顶尖模型普遍选择远超任务需要的高权限技能,端到端成功率最高仅14.3%。

谷歌向“AI优先“智能手机迈出关键一步
谷歌在Android Show发布会上宣布,将Gemini更深度整合至Android系统,推出名为"Gemini Intelligence"的升级功能。该功能可跨应用处理日常任务,包括自动填写表单、安排日程、生成购物清单及自定义小组件等,无需用户频繁切换应用。此外,Gboard新增"Rambler"功能,可自动过滤语音输入中的口误和填充词。Gemini Intelligence将率先登陆三星Galaxy和谷歌Pixel手机,并支持Android Auto、Wear OS及智能眼镜。

荷兰Nebius团队:给AI“起草员“瘦身,大模型推理速度最高提升5倍的秘密
荷兰Nebius团队提出SlimSpec,通过低秩分解压缩草稿模型LM-Head的内部表示而非裁剪词汇,在保留完整词汇表的同时将LM-Head计算时间压缩至原来的五分之一,端到端推理速度超越现有方法最高达9%。
2020
05/11
18:50
分享
点赞

谷歌向"AI优先"智能手机迈出关键一步
谷歌为Gboard引入Gemini语音听写功能,听写类初创企业面临压力
Android 17 九大重磅新功能抢先看
OpenAI成立独立咨询业务,加速企业AI落地部署
Oracle加快安全补丁发布节奏以应对AI网络安全威胁
Googlebook:专为安卓用户打造的理想笔记本电脑
HPE重构私有云产品栈,助力企业应对VMware迁移与AI需求
谷歌扩大Quick Share与AirDrop互通范围,新增QR码云端分享功能
Chrome for Android迎来完整Gemini集成与自动浏览功能
2026年Android Auto重大更新:视频应用、音乐升级与Gemini智能体验全面来袭
iOS 26.5更新苹果地图两项新功能详解
莱迪·嘉嘉全新演唱会电影将于本周四登陆Apple Music独家流媒体
威瑞森商务宣称无边界物联网时代已经到来
2025年MWC大会:诺基亚通过私有网络增强海运业务并推进API发展
Microsoft 新推出的 Phi-4 AI 模型:小巧身材蕴含强大性能
Dragonwing 腾飞:提升高通工业和嵌入式物联网产品布局
Bridge Alliance 与 Telna 就 eSIM 达成战略合作伙伴关系
沙特太空部门携手 Myriota 打造超低功耗物联网连接
专访:三星为何将这家英国初创公司推至台前
SUSE发布SUSE Edge Suite 与Edge 3.2 ,助力零售企业实现无缝化运营
高通在汽车和工业物联网领域的革命性转型
Scale Computing 声称在 VMware 替代品需求推动下实现销售增长
