
小米AI团队发布新论文 基于弹性搜索(宏观+微观)在超分辨率问题上取得成果 原创
北京下雪了,我先来拍两张。——咔嚓!
图像是最为普及的一种信息载体。而对于如何改善图像质量,提高图像的清晰度,就变成了一个图像处理领域的难题,图像超分辨率技术因此而生,并成功应用到了计算机图像视觉、医学等领域。
近日,小米雷军发微博表示,“来自小米最新出炉的论文,基于弹性搜索在图像超分辨率问题上取得了令人震惊的结果,该模型已开源。”随后与网友评论互动中,雷军还指出“现在相机技术高度依赖人工智能图像技术的进步!”可以看出,这项成果可能在不久的将来会在小米的硬件产品中得到应用。
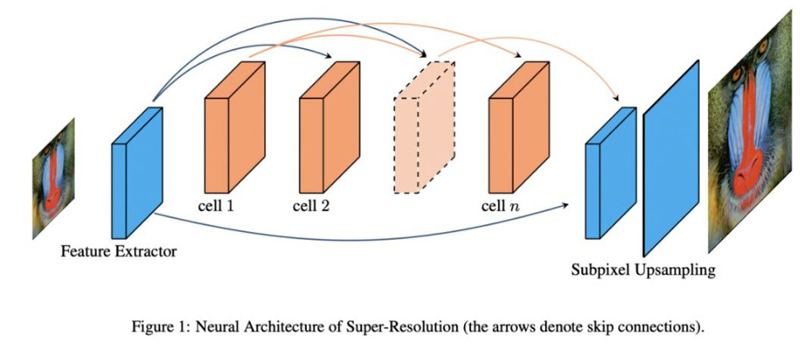
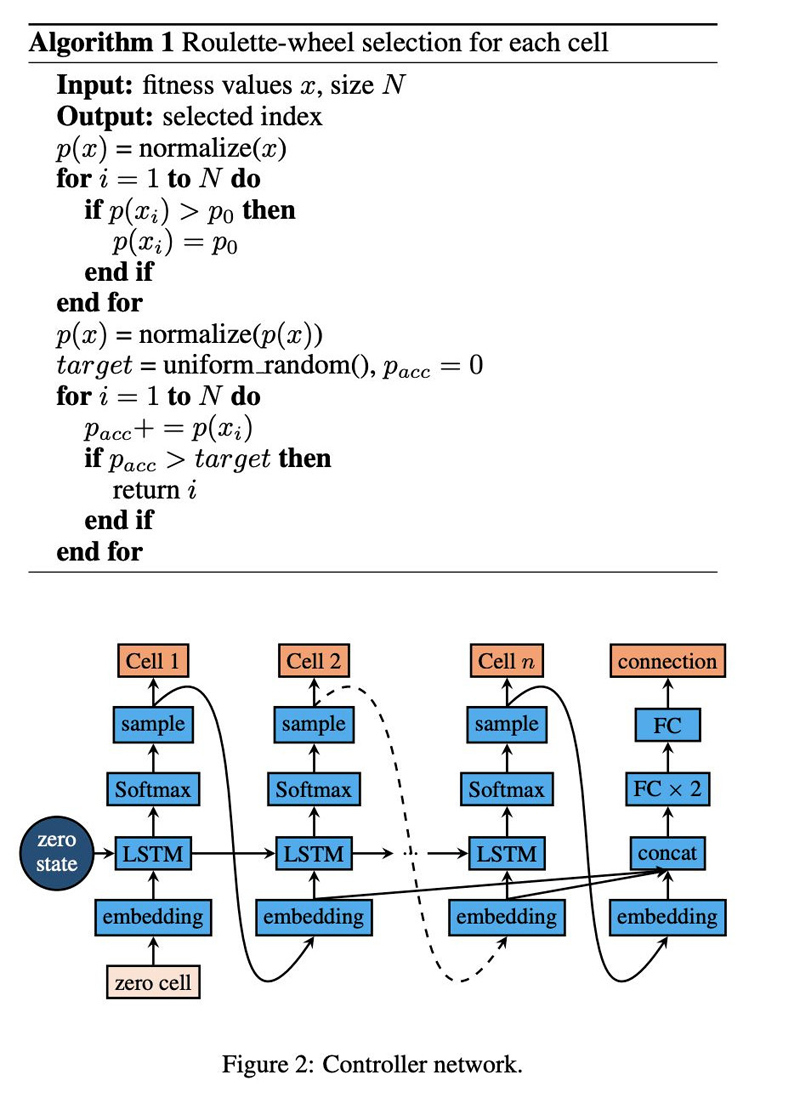
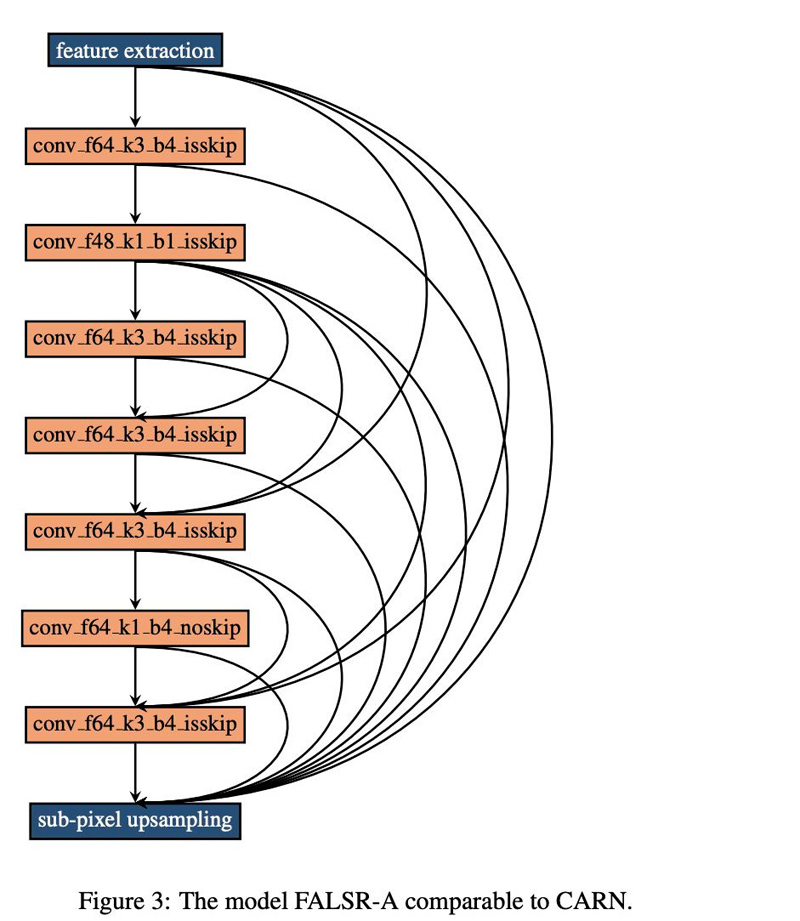
论文的全称为《Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search》(论文下载链接:https://www.paperweekly.site/papers/2786),论文基于弹性搜索(宏观+微观)在超分辨率问题上取得了令人震惊的结果。在相当的 FLOPS 下生成了多个模型,结果完胜 ECCV 2018 明星模型 CARNM(乘加数参数数量少,PNSR/SSIM 指标高,文中称 dominate),这应该是截止至 2018 年可比 FLOPS 约束下的 SOTA(涵盖 ICCV 2017 和 CVPR 2018)。而达到这样的效果,论文基于一台 V100 用了不到 3 天时间。
此外,论文还给出了几个前向模型。要知道上一篇论文中他们初步结果是击败 CVPR 2016,才半个月时间就提升这么大,这也进一步验证了 AutoML NAS 技术的强大和可怕。需要指出的是,该项技术具有一定的普适性,理论上可以应用于任何监督学习,值得关注和学习。
来源:至顶网商用办公频道
好文章,需要你的鼓励


派拉蒙CIO规划AI规模化路径,CTO即将卸任
Paramount正加速推进AI布局,同时面临CTO Phil Wiser五月底计划离职的人事变动。在收购华纳兄弟探索公司接近尾声之际,Paramount CIO Lakshman Nathan在路透社举办的Momentum AI大会上分享了公司AI战略:公司已在隐私、法务及代码开发等领域部署AI,两天内即可完成应用测试交付。Paramount采取开放探索与治理并行的策略,借助智能体AI推动企业级应用整合,同时稳步处理多次并购带来的遗留系统问题。

字节跳动研究团队让AI“老师“学会看学生眼色——自适应知识暴露如何让小模型突破学习瓶颈
字节跳动团队提出ATESD,通过让AI"老师"自适应控制向"学生"暴露多少参考推理过程,突破了自蒸馏训练中全量暴露的默认设定,在竞赛数学推理上显著提升小模型性能。

量子计算面临安全威胁与人才短缺双重挑战
量子计算行业正面临两大迫切问题:安全威胁与人才短缺。随着"Q-Day"临近,量子计算机或将破解RSA加密体系,威胁银行、医疗、政府等关键基础设施安全。NIST要求2035年前完成向后量子密码学的迁移。与此同时,行业人才严重匮乏——目前仅有3万名量子专业人员,而2029年需求将达25万人。据麦肯锡预测,量子计算到2035年将创造3万亿美元经济机遇。

AI视频理解的“作弊“漏洞被揭穿了——来自StepFun团队的深度修复方案
StepFun团队发现主流全感官AI评测存在"视觉作弊"漏洞,发布OmniClean清洁评测集,并提出三阶段OmniBoost训练方案,让30亿参数小模型媲美300亿参数大模型。
2019
02/19
16:48
分享
点赞

量子计算面临安全威胁与人才短缺双重挑战
IrisGo:由吴恩达投资的AI桌面智能体,让工作流程自动化成为现实
OpenAI宣称用AI推翻了一个困扰数学界近80年的猜想
Linus Torvalds坦言对AI又爱又恨:工具有用,但挑战真实存在
Hovercraft:让视频通话演示更自然的 Mac 应用
tvOS 27将为Apple TV 4K带来全局文字放大新功能
比亚迪新款快充电动车订单突破10万辆,产能严重告急
博杰斯快餐连锁推出电动汽车快速充电服务
YouTube Shorts推出AI混剪功能,借助Gemini实现视频重塑
四大AI模型运营电台六个月,结果一团糟
Clouted:用AI智能体消除短视频爆款的不确定性
Anthropic每月向xAI支付12.5亿美元算力费用
